物理ベースのキャラ(アクティブラグドール)を、強化学習で自律的に歩けるようにするための手順です。
関連
- ◯
- 物理ベースのキャラを強化学習向けに調整する:Unity (ML-Agents (Walker)) , UnityChan, VRM (VRoid) , DAZ
訓練する
まずコンテナ側で、次のようにコマンドを実行します:
$ cd /opt/ml-agents
$ mlagents-learn config/ppo/Walker.yaml --run-id=${ID_RUN}次にUnity 側で、キャラクタに付いているコンポーネント「BehaviorParameters」のニューラルネットのモデル「Model 」の値を、空にします(これでキャラクタは、そのモデルで動くことはなくなります)。この状態でゲームを実行することで、学習が始まります:[※1]
学習を終えるには、ゲームをストップさせます。[※2][※3]
- ※1
- コンテナ側の強化学習用のプログラム(Python)とUnity との間の連携は、ポートによる通信で行われています(既定のポート番号は「5004」)。
- ※2
- 学習を再開するときは、コンテナ側のコマンドに引数「--resume」を付けることで、学習を終えた時点から始めることができます。
- ※3
- この例では3千万ステップまで実行していますが、クラウドのサーバで24時間以内に終わっています……なお訓練の動画は、じっさいの訓練時の画面ではなく、生成されたニューラルネットを使ってあとから編集したものです(サーバにはビデオモニタがないので、ゲーム画面は表示されません)……髪の毛のゆれなども編集時に追加したもので、訓練時は、不要な物理演算はすべて切っています。
適用する
学習の結果を反映したニューラルネットのモデルは、次に格納されます:[※1]
- ・
- ${DIR_ML_AGENTS}/ml-agents/results/${ID_RUN}/{$NNM}.onnx
これを、キャラクタに付いているコンポーネント「BehaviorParameters」のニューラルネットのモデル「Model 」に適用します。学習がうまくいっていれば、キャラクタが目標に向かい、倒れずに歩き出すはずです:
- ※1
- ファイルは指定のステップ数ごとに、指定の上限数まで保存されますが、上限を超えると最初のファイルから順に削除されます。
ちなみに通常の体型の(SDタイプではない)VRoid モデルに、既定のスクリプトを適用すると、たいてい次のように<摺り足>っぽい歩き方になるはずです(これはML-Agents のWalkerRagdoll も同様です):
たしかに摺り足の方が、大きく重心がブレることがないので安定はしているのでしょうけど……(SDタイプの場合は重心がかなり上にあって足も短いので、片足を前に踏み出すコストが比較的小さくなり、大股で歩けるのかもしれませんーー大股の方がターゲットに対するボディー各部の速度は大きくなるので、それだけ報酬も大きくなります……ただし方向転換は苦手のようですが)。[※1][※2]
- ※1
- 摺り足の歩き方もそれなりに面白いので、アクションゲーム風(ゾンビもの)にしてみましたーー押し返されたときの慌てた動きが人間っぽくて、通常のアニメーションより臨場感がありますね……あと投げられて着地するときに、タイミングがよければ倒れずに頑張っていたりもします(狭い部屋でこれだけ広いシーンをパススルーにすると2Dの動画ではかなり違和感があるので、VR版での出力です):
- ※2
- 次は、物理演算+自律行動+リアル系とアニメ系の融合+現実と仮想の融合……といろいろ詰め込んでみましたが……かなりカオスです:
確認する
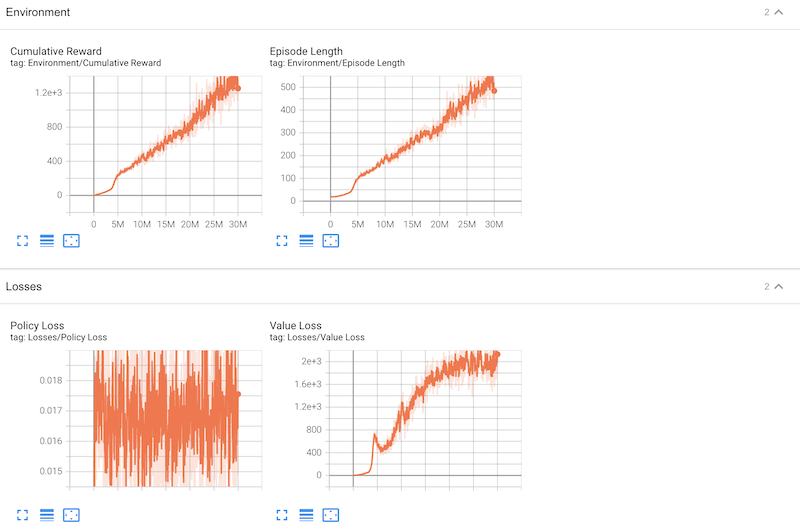
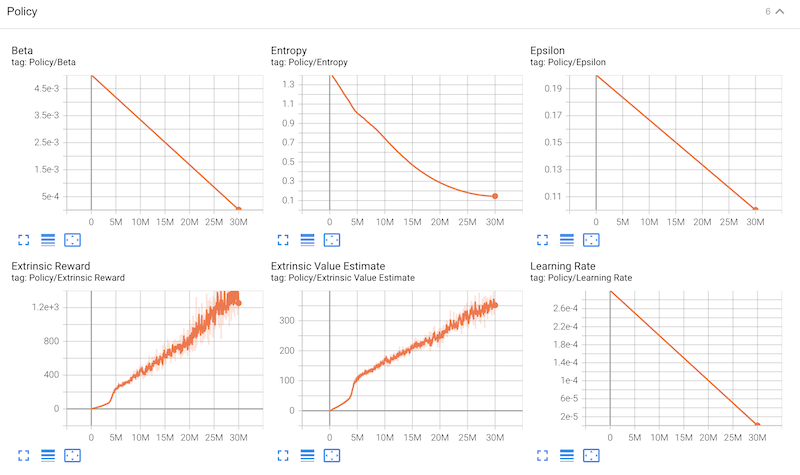
なお学習の状況は、「tensorboard 」のグラフでも確認できます:[※1]
- ※1
- 学習の状況をグラフで確認するには、ポート「6006」にアクセスします。