方策ベースの強化学習の基本、方策勾配法を「ゼロから作る〜4」のコードで実行します。
関連
- ◯
- 強化学習のためのシンプルな環境:Farama Gymnasium, OpenAI Gym, Docker, X Window System, Pyglet, pygame, tkinter
検証
- ・
- インタプリタ:Python 3.8
- ・
- ライブラリ:OpenAI Gym 0.26
- ・
- ライブラリ:DeZero
方策勾配法×倒立振子:OpenAI Gym (CartPole), PyTorch, DeZero
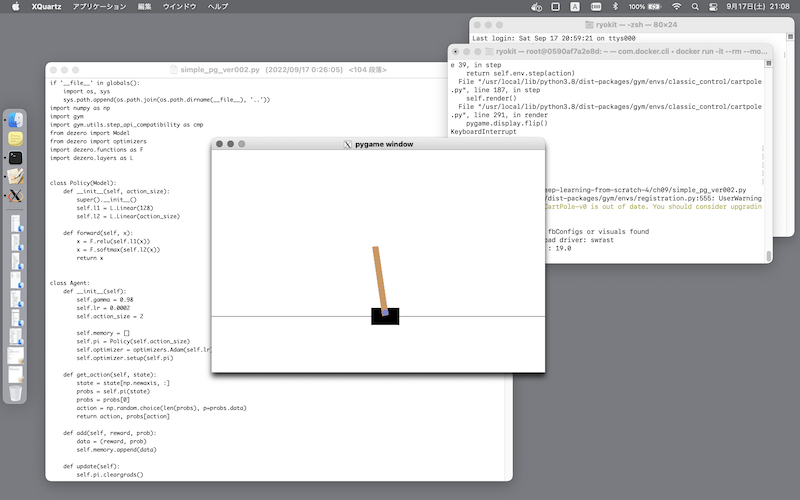
方策ベースの強化学習の基本、方策勾配法を使って、倒立振子を学習させます。
倒立振子はOpenAI Gym (CartPole) の環境を、方策勾配法のコードは「ゼロから作る〜4」のものを使います:[※1]
$ pip install torch
$ pip install dezero
$ cd ${DIR}
$ git clone --depth 1 https://github.com/oreilly-japan/deep-learning-from-scratch-4
$ python ${DIR}/deep-learning-from-scratch-4/pytorch/simple_pg.py # PyTorch 版
$ python ${DIR}/deep-learning-from-scratch-4/ch09/simple_pg.py # DeZero版
- ※1
- このコードは機械学習のフレームワークを使っていますが、とくにフレームワークのDeZero版は、シンプルな学習向けです(「ゼロから作る〜3」)ーーなので、まずフレームワークの大まかなレベルで、方策勾配法の全体を把握できます。そしてフレームワーク内部の動きについて知りたければ、さらに(解説つきで)細部を追っていくことができる環境になっています:
- ・
- ゼロから作るDeep Learning ❹
- ・
- ゼロから作るDeep Learning ❸
コードの修正:対応:OpenAI Gym v0.26
とりあえずDeZero版については、Farama Gymnasium 0.26 、OpenAI Gym v0.26に対応する修正点も挙げておきます:[※1]
- ・
- 修正前(ch09/simple_pg.py):
import gym
env = gym.make('CartPole-v0')
state = env.reset()
next_state, reward, done, info = env.step(action)
- ・
- 修正後(ch09/simple_pg.py):
import gymnasium as gym # Farama Gymnasiumを使う場合
env = gym.make('CartPole-v0', render_mode='human') # 訓練の画面を表示する場合
state, _ = env.reset()
next_state, reward, done, _, info = env.step(action)
- ※1
- 後方互換性を確保するためのユーティリティも提供されていますが、素直にこのバージョンの仕様向けにコードを書き換えた方が、見た目はいいですね……