

ComfyUI は、画像生成アプリのひとつです。
ノードと呼ばれるパーツのつながりが、生成の流れを分かりやすくみせてくれますーーここではそれを、<なぜそこにつなぐのか>という視点からみていきます。[※1][※2]
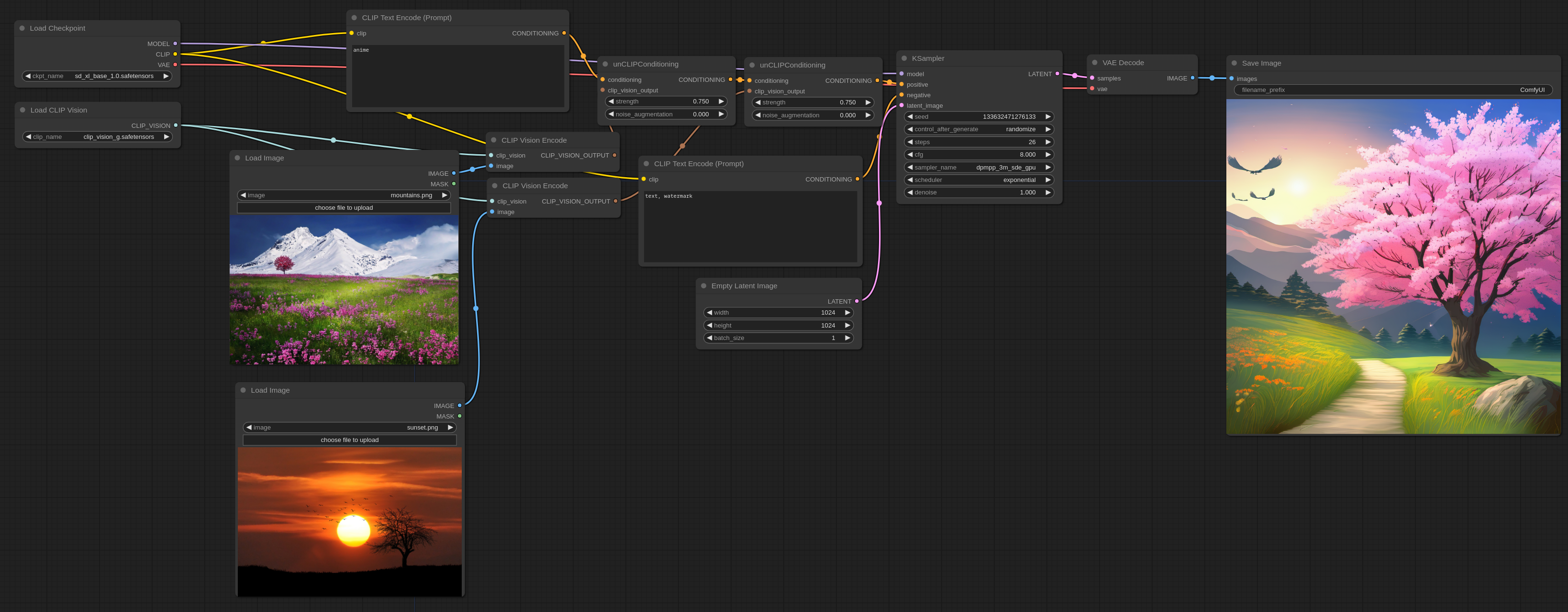
- ※1
- この記事は、アプリのなかで起きていることを、より具体的にイメージできるようにと書いています(それを目指しています)ーーここでは設置や利用のしかたは書いていませんが(別掲)、その作りと流れを押さえることで、やみくもな試行錯誤でなく、より効率的に ComfyUI を使えるようになるかもしれませんし(それにしくみを知ること自体、ワクワクしますしね)。
- ※2
- この記事で注釈は 2 種類あり、[→N]は補足、[※N]は雑記ですーー補足では、本文では書いていないことを、より詳しく説明しています。
関連
- ◯
- ComfyUI を、クラウドのコンテナに設置する:ComfyUI, Docker, GCP
- ◯
- ComfyUI の API を使う:ComfyUI, API, JSON, Python, Docker, GCP
- ◯
- ComfyUI で、画像処理のノードを作る:Python (PIL, Torchvision), ComfyUI
- ◯
- ComryUI で、音声認識/音声合成/チャット/感情分析のノードを作る:Docker, Dynamic DNS, SSL/TSL, Python (Transformers, aiohttp), JavaScript, ComfyUI
- ◯
- ComfyUI 向けの Krita プラグインを自作する:ComfyUI, Krita, WebSocket, Python, PyQt
- ◯
- AI で生成した<動くキャラ>と、VR/MR で対面する:ComfyUI, GIMP, Virtual Desktop, Quest
- ◯
- AI で生成した画像を、日本語で解釈させる:ComfyUI, LLaVA, Docker, GCP
目次
- ◯
- 背景
- ◯
- 問題
- ◯
- 対応
- ◯
- 設計:操作(UI)
- ◯
- 設計:内部(module)
- ◯
- 設計:連携(API)
- ◯
- 関連:SD モデルの世代
- ◯
- 関連:SD モデルの周辺
- ◯
- 構成:SD モデルの構成
- ◯
- 遷移:基本:グラフ
- ◯
- 遷移:基本:ノード:Load Checkpoint
- ◯
- 遷移:基本:ノード:CLIP Text Encode (positive / negative)
- ◯
- 遷移:基本:ノード:Empty Latent Image
- ◯
- 遷移:基本:ノード:KSampler
- ◯
- 遷移:基本:ノード:VAE Decode
- ◯
- 遷移:基本:ノード:Preview Image / Save Image
- ◯
- 遷移:補足:ノード:Load Image / VAE Encode
- ◯
- 遷移:補足:ノード:Upscale Latent / Image Upscale with Model/ Upscale Model Loader
- ◯
- 遷移:補足:ノード:Conditioning Set Area / Conditioning Combine
- ◯
- 構成:拡張:SD モデルのマージャ
- ◯
- 構成:拡張:SD モデルのチューナ/コンディショナ
- ◯
- 遷移:拡張:SD モデルのチューナ:DreamBooth
- ◯
- 遷移:拡張:SD モデルのチューナ:LoRA (LoRA Loader)
- ◯
- 遷移:拡張:SD モデルのチューナ:HyperNetwork (HyperNetwork Loader)
- ◯
- 遷移:拡張:SD モデルのチューナ:IP-Adapter (Load IPAdapter)
- ◯
- 遷移:拡張:SD モデルのチューナ:AnimateDiff (AnimateDiff Loader)
- ◯
- 遷移:拡張:SD モデルのコンディショナ:Textual Inversion
- ◯
- 遷移:拡張:SD モデルのコンディショナ:ControlNet (Load ControlNet Model, Apply ControlNet )
- ◯
- 参照:書籍/記事/動画
背景
2022 年 08 月、画像生成の新しいモデルが公開されました。[※1][※2]
SD(”Stable Diffusion”)というそのモデルが画期的だったのは、それまでの画像生成サービスなどと違い、だれでも使えるようなかたち(オープンソース)で提供されたことです。
結果、爆発的に普及し、いまもこのモデルに向けて、いろいろな手法が研究・開発され続けているわけですね。[※3]
- ※1
- SD モデルは、ミュンヘン大学の CompVis グループが開発し、Runway ML 社/Stability AI 社と共同で公開していますーーこのため、共有サイト”Hugging Face”上のモデルも、v1.4 までは CompVis グループ、v1.5 は Runway ML 社、v2 - XL 以降は Stability AI 社の公開と、けっこうややこしい状態です:
- ・
- https://huggingface.co/CompVis
- ・
- https://huggingface.co/runwayml
- ・
- https://huggingface.co/stabilityai
- ※2
- 2024 年 3 月、創業者のモスタク氏が、Stability AI 社を離れることになりましたーーもともと「AI の民主化」を掲げて創業し、辞任後も「AI の分散化(技術も組織も)」に言及しているので、同社のオープンソースに対する方針は変わらなそうですが(モスタク氏自身は、辞任後も同社の株式を保有しています)。
- ※3
- いっぽう社会に混乱ももたらしましたーーとはいえそれは、それまでの生成サービスがはらんでいた問題が顕在化したものといえます(隠蔽・焼畑・氾濫・搾取・独善)ーーいずれにしてもコンテンツは、固有の文化のなかで、ヒトが作ってきた/作っていくしかないものです(機械をヒトと同じように作り、生死とタイムスケールを共にすることで、文化を共有できるようになるか、というのは技術面でも費用面でも難しい問題ですし)ーーいまは、ヒトと機械が協業していけるよう、その土台を倫理と法律で固めようとしているところですね……
問題
そして SD モデル向けのアプリも、いろいろ提供され始めました。
ただ問題は、たくさんの生成手法があるので、アプリ上でそれらがたがいにどう影響するのか、よく分からなくなってくることでしょうか。
分かりにくさのひとつに、それらのつながりが、操作する画面(UI)の裏で<配線>されている、という面もありそうです:
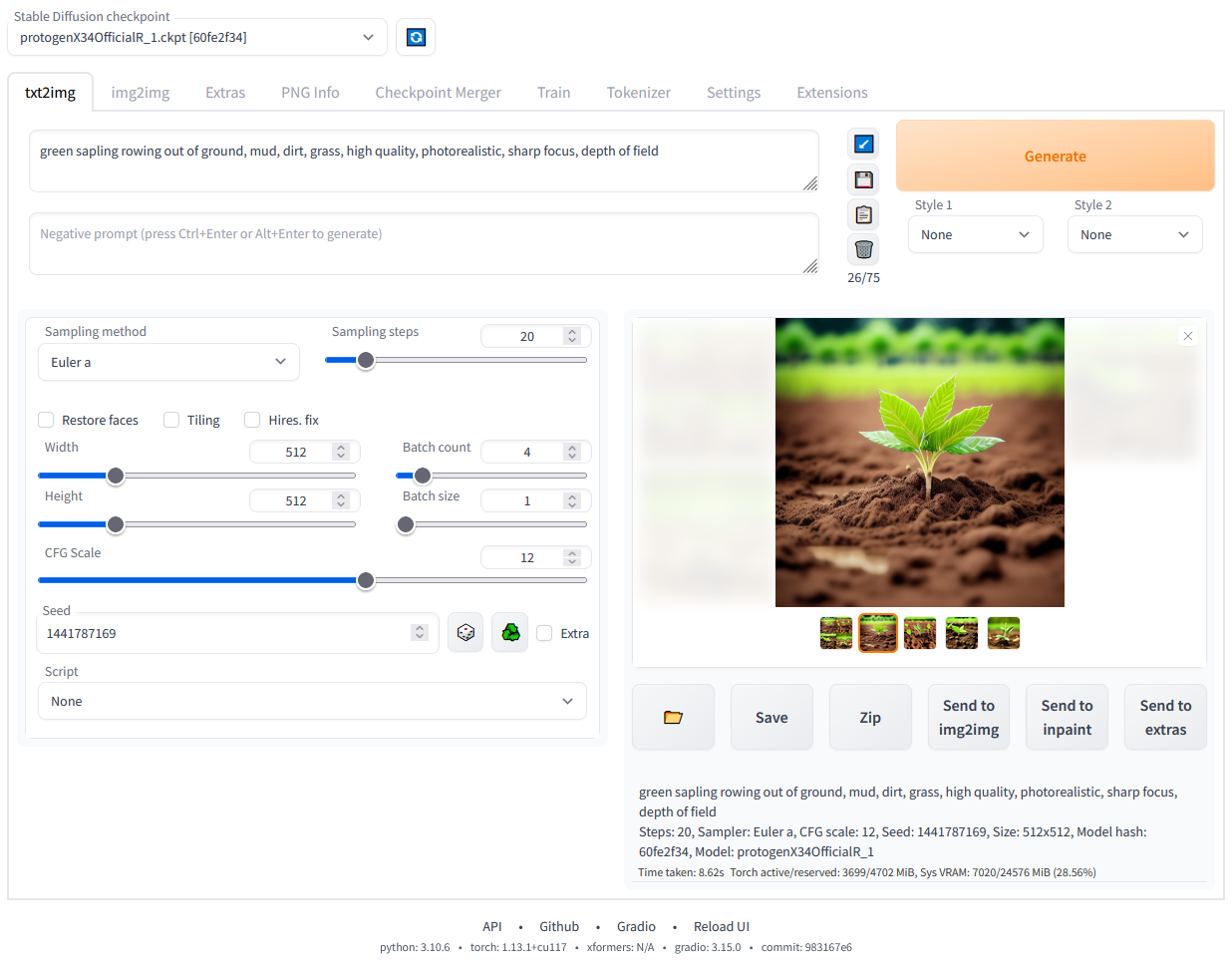
- ※1
- これは AUTOMATIC1111 氏が提供する、”SD web UI”の画面ですーーなおここで例に出しているのは、おそらくもっともよく使われているアプリだから、というだけの理由ですーー同氏は SD モデルが公開された黎明期から、だれもが使えるように GUI のアプリを提供し、コミュニティの広がりに大きな貢献をしてきたわけですし(GitHub アカウントの一時削除という事件もありましたが)。
- ・
- https://github.com/AUTOMATIC1111/stable-diffusion-webui
対応
なら、その<配線>を表に出してしまおう、という発想が出てきます。
データフロープログラミングという手法が、そういう表現を採用していますーー端的には、データの流れを点と線で表します。点をノード、線をエッジやリンク、それら全体をグラフ、と呼んだりします。[※1]
ComfyUI は、SD モデルを、データフロープログラミングのかたちであつかえるようにした実装ですーーSD モデルの公開から半年後、2023 年 03 月に提供されました:[※2][※3][※4]
- ※1
- ノードそのものが UI のパーツになっているので、画面の構成そのものを自分で作っていける、という利点もありますーー状況や要望に応じた、もっとも見やすい/シンプルな画面にできるわけですね。
- ※2
- ただし基本の構造は、ループのない一方向のグラフ(DAG)、といっていいものです(部分的に分岐・反復ができるノードはあり)。またデータフロープログラミングの醍醐味は非同期にあるわけですが、ComfyUI については、実行は逐次的です(非同期ノードも追加(2025.07))。
- ※3
- https://github.com/comfyanonymous/ComfyUI
- ※4
- 開発したのは comfyanonymous 氏です。なお同氏はその後、Stability AI 社で仕事をするようになり、同社の生成モデル群を、ほぼ公開と同時に ComfyUI に対応させてきました。しかし SD 3 の実装を最後に辞職(2024.06.17)、独立した組織として活動を始めています(2024.06.19)ーーこの組織には、”StableSwarmUI”(ComfyUI をバックエンドに使った Stability AI 社の画像生成アプリ)を開発した人もいるようですね:
- ・
- https://www.comfy.org/
設計:操作(UI)
ComfyUI は、その UI に ”litegraph.js”を採用しています。
これはウェブブラウザ向けのデータフローアプリで、プログラミング言語の”JavaScript”で書かれたものです:[※1][※2]
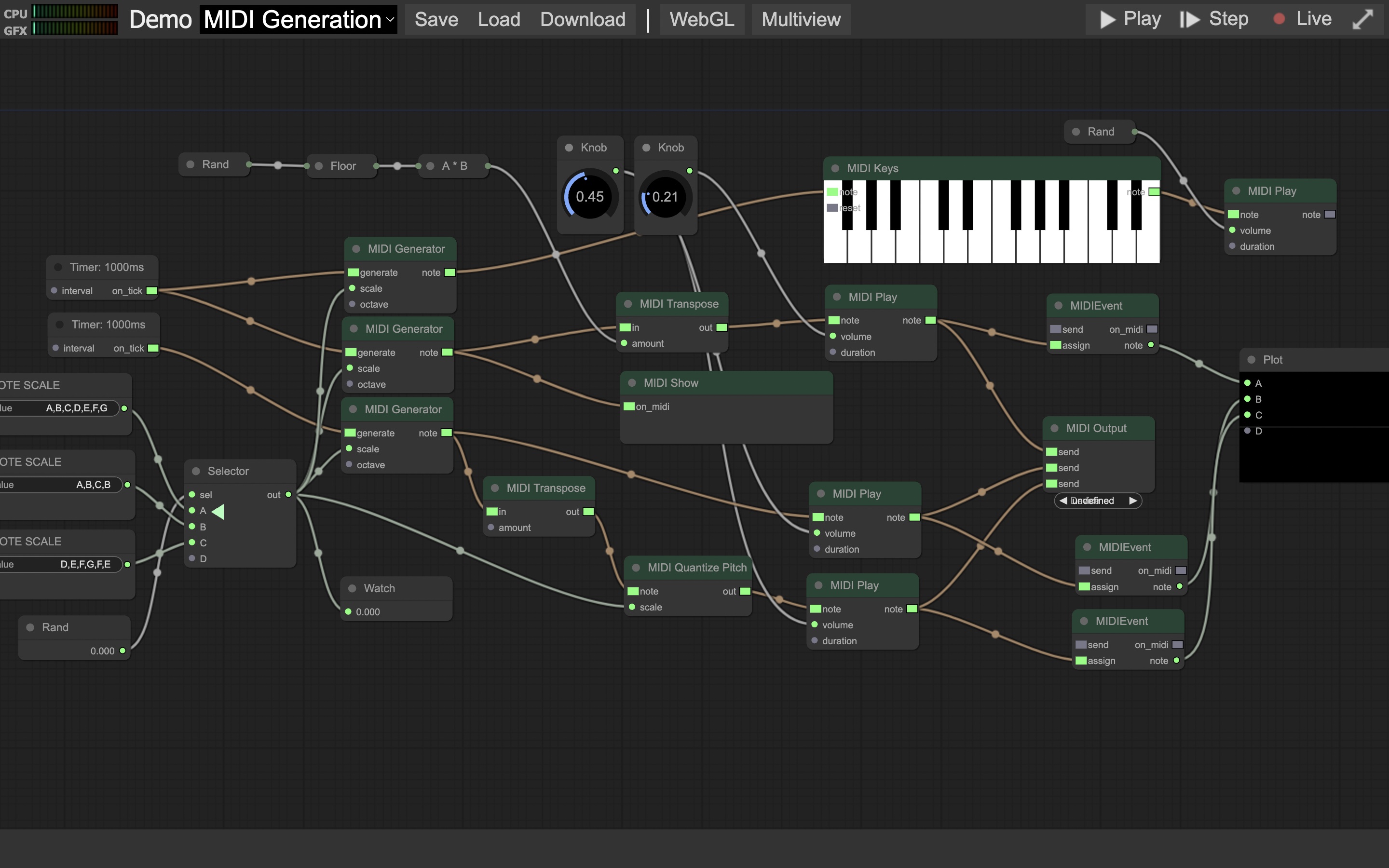
ただ機械学習のプログラムは”Python”で書かれることが多いため、ComfyUI は、この言語でノードのプログラムを記述できるようにしていますーーここが、litegraph.js との大きな違いです。[→1][※3]
- →1
- 独自ノードは、次のように Python で記述することができますーーもちろん、UI の部分(/web)を変更する場合は、JavaScript で記述する必要がありますが:[※4]
- ・
- https://github.com/comfyanonymous/ComfyUI/tree/master/custom_nodes
- ・
- https://note.com/nyaoki_board/n/n96ab9293291c
- ※1
- https://github.com/jagenjo/litegraph.js
- ※2
- このフレームワークは、ミラー・パケット氏の”Pure Data”などに触発されて開発されていますーーこちらのアプリも本体は音楽・音声向けですが、有志による拡張で、画像・映像・3D(物理演算)にも対応しています。それらさまざまなオブジェクトを、原理に近いところから作っていけるのが特徴です。オープンソースの草分でもあり(”PD”は「パブリックドメイン」に掛けてあります)、メディアアートの制作にも使われていたり:
- ・
- http://msp.ucsd.edu/software.htm
- ※3
- 機械学習〜深層学習のプログラムには、Python で書かれたものがたくさんあります(機械翻訳、言語生成、音声認識、音声合成、画像認識、画像生成、映像生成、……)。ComfyUI はその仕様から、それらのモデルもあつかうことができます(もちろんインタフェースを書けば、ですが)ーーここにさらに litegraph.js のライブラリ群(音声・音楽関係)も統合したら、かなり楽しめそうです。
- ※4
- ノードを自分で作ることがなくても、これらの記述ルールを知っていれば、いろいろ便利ですーーたとえば、提供されているカスタムノード群のパッケージから、必要なものだけを選んで使う、など。
設計:内部(module)
ComfyUI の Python による記述は、UI と分離できるように設計されています。[※1]
なので、UI をべつのものに変えることも、それなりに容易ですーー次は、3D 制作アプリ”Blender”のノードで、ComfyUI のフローを実装した例です:[※2][※3]

- ※1
- https://blog.comfyui.ca/comfyui/update/2023/05/18/ComfyUi-is-4-months-old.html
- ※2
- https://github.com/AIGODLIKE/ComfyUI-BlenderAI-node
- ※3
- Blender は、プラグインの作成に Python を使うことができますーーというより、アプリの動作は、ほぼ Python のシェルに包まれているといった方がいいかもしれません(MayaのMEL/Pythonに相当)。たとえば、3D オブジェクトへのさまざまな操作に連動して、それを実行しているスクリプトを閲覧〜実行できるコンソール画面があります(Python Console)。操作を自動化したいときは、そのコンソールから直前に行われた<動作>の箇所をコピペすることで、すぐに動くものが作れたりします。
設計:連携(API)
ComfyUI は、外からプログラムで操作するやり方(API)も提供していいます。[→1]
馴染みのあるアプリの UI から、ComfyUI のさまざまな機能を利用できるわけですね(ウィンドウを使う GUI から、コマンドを打つ CLI まで)ーー次は、画像編集アプリ”Krita”で、ComfyUI を使えるようにしたプラグインです:[※1][※2]
- →1
- ComfyUI の API は、そのフロー(ワークフロー)を JSON に変換したものに変更を加えていくという、とても分かりやすいものになっています:
- ・
- https://github.com/comfyanonymous/ComfyUI/tree/master/script_examples
- ※1
- https://github.com/Acly/krita-ai-diffusion
- ※2
- Krita は、プラグインの作成に Python を使うことができますーーこの言語が選ばれたのは、支援者からの支持が大きかったからのようですね(UNIX の GUI には X Window System が使われていますが、そこで動かすツールキットには、2 つの大きな陣営があります。GTK を使う GNOME 陣営と、Qt を使う KDE 陣営というーーもともと GNOME の画像編集アプリ(フォトレタッチアプリ)には GIMP がありましたが、その対抗?として開発されたのが Krita ですーーユーザの要望を積極的に取り入れていった結果、お絵描きアプリとしての機能が強化されてきました。スクリプティング機能(Python/PyQt)の導入も、その一貫です):
- ・
- https://docs.krita.org/ja/user_manual/python_scripting/introduction_to_python_scripting.html
関連:SD モデルの世代
SD モデルには世代があります。
ただどの世代も、訓練に使ったデータ(画像群)が違います。またモデルそのものも、周辺の構造の違い(SD 1 → 2)、主要な構造の違い(SD → SDXL)、構造と手法の抜本の違い(SD → SD 3)、がありますーーなので、世代間で互換性はありません:[※1]
- ・
- 2022.08 …… SD 1
- ・
- 2022.11 …… SD 2
- ・
- 2023.07 …… SDXL 1[※2]
- ・
- 2024.06 …… SD 3[※3][※4][※5]
- ※1
- ComfyUI は、正式に公開されたすべての世代のモデルをあつかうことができます。また世代が変わっても、つなぎ方にほぼ違いはありません。
- ※2
- SDXL では、テキストエンコーダの数が2コに増えています(CLIP-G / CLIP-L)。またリファイナと呼ばれる、生成画像の品質を向上させる追加の構造がありますーーComfyUI なら、この構造のためのノードを追加するのは難しくありません(次にリファイナの効果ふくめ、つなぎ方の分かりやすい解説がありますーーただ劇的な効果があるわけではないので、使っていないワークフローもけっこうありそうですが:)
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/sdxl/
- ・
- https://webbigdata.jp/post-19966/
- ※3
- SD 3 は、パラメータ数に応じ、4つのモデルが用意されています(1B / 2B / 4B / 8B)。いずれも、構造としてトランスフォーマ(DiT)の導入、手法としてフローマッチング(FM)の導入、となっています。また、テキストエンコーダの数も3コに増えています(CLIP-G / CLIP-L / T5)。このうち T5 はテキスト〜テキストの言語モデルですが、これで複雑な言い回しもエンコードすることができますーーなお現時点では(2024.06)、プレビュー(2024.03)を経て、2B のモデルのみローカル向けにリリースされています:
- ・
- https://ja.stability.ai/blog/stable-diffusion-3
- ※4
- ビジョントランスフォーマ(ViT)は、画像をパッチに分けて、トークンのようにトランスフォーマに与える手法です。その構造を拡散モデルに流用したのが、拡散トランスフォーマ(DiT)です(入力〜出力や条件づけの違いはあるものの)ーーなお SD 3 では、テキストとイメージをひとつのアテンション機構で合成する構造になっています(MMDiT)ーートランスフォーマの大きな特徴として、パラメータ数が増大するほど性能も向上する、というスケーリング則があります。 SD 3 にもその傾向はみられますが、性能向上を追求するには、相応のリソースを投入する必要がありますーーたとえば DiT は OpenAI 社の動画生成モデル”Sora”も採用していますが、動画ということもあり、学習に必要なリソースのケタが違いますね……
- ・
- https://arxiv.org/abs/2212.09748
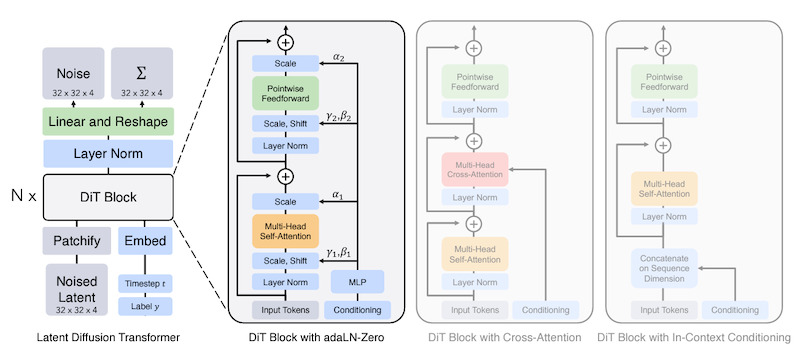
- ※5
- フローベースモデルは、単純な分布を複雑な分布に変えていく手法です。尤度関数(負の対数尤度など)をそのまま学習に使える、というのが大きな利点ですーーこの正規化フロー(NF)を連続化したものが連続正規化フロー(CNF)ですが、計算グラフの全てを使う必要がありました。それを(拡散モデルと同様に)計算グラフの一部を使えるようにしたのが、フローマッチング(FM)ですーーこれの条件つきフローマッチング(CFM)には、最適輸送を使うものもあるようですが(OT-CFM)ーーなお SD 3 では、分布間を線形に結ぶフローマッチングの手法が採用されていて(Rectified Flow)、訓練を比較的シンプルにできる、という特徴があります:
- ・
- https://lilianweng.github.io/posts/2018-10-13-flow-models/
- ・
- https://zenn.dev/fusic/articles/ml-flow-matching
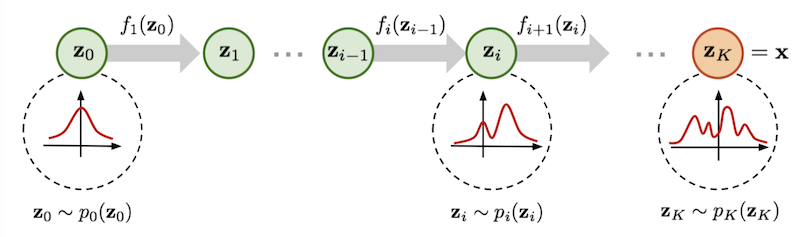
関連:SD モデルの周辺
SD モデルとその周辺にも、さまざまな生成モデルがあります。
2023 年 11 月、画像をより高速に生成する LCM (潜在一貫性モデル)が提案されました。このモデルは理論上、画像の生成を 1 ステップで行えますーーそののち、Stability AI 社も、ADD という技術を使って、高速画像生成のモデルを提供しています。[※1][※2][※3]
また Stability AI 社は、2023 年 3 月に SD 2 の派生モデルとして、画像から意味を抽出する unclip モデルを公開しています。そして 2024 年 02 月には、チューニングがよりかんたんになるモデルを採用した”Cascade”を公開しました:[※4]
- ・
- CM > LCM
- ・
- ADD > SDXL Turbo
- ・
- LDM > SD 1, SD 2 (> SD 2 unclip) , SDXL 1
- ・
- FM > SD 3
- ・
- Würstchen > Stable Cascade
さらに 2023 年 11〜12 月、Stability AI 社は、映像を生成するモデルや、3D モデルを生成するモデルを、順次公開しています:[※5]
- ・
- SVD (Stable Video Diffusion)
- ・
- Zero123 > Stable Zero123
また ComfyUI の作者が Stability AI 社を辞めたことにともない、SD 以外のモデルについても注目が集まっていたりします(ComfyUI での動作も、それぞれのコミュニティから報告が上がってきています):[※6]
- ・
- Hunyuan-DiT
- ・
- PixArt-Σ
- ・
- Lumina-T2X
- ※1
- LCM の元になっている CM(一貫性モデル)は、<ノイズが追加されたどの時点の画像からも、元の画像を推定できる>よう訓練しています(そのような推定をする関数自体は仮定のものですが、その損失関数を得ることができる(=訓練できる)、というのが驚きです。スコアベースモデルからの蒸留も示されていますが、教師モデルがなくても学習できる、とのこと)。ただし CM は理論を検証するためのモデルだったので、画像は素のままで/条件づけの過程も省いています。これを潜在空間の画像にし/条件づけもできるようにしたのが、LCM です。
- ・
- https://arxiv.org/abs/2303.01469
- ・
- https://zenn.dev/discus0434/articles/484be111f7862d
- ※2
- LCM を SD モデルの LoRA として訓練したモデルもあり、これは ComfyUI であつかえますーーこれでほぼリアルタイムな画像生成が、既存の環境でもできるようになりました。とくに画像編集アプリ(Krita など)から ControlNet を使って、落書きやポーズからリアルタイムに生成画像を修正していく手法は、画像生成に初めて、<手描きの感覚>を導入したといえるかもしれません:
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/lcm/
- ※3
- この”Turbo”は、そのまま ComfyUI であつかえます:
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/sdturbo/
- ※4
- この”Cascade”は、クロスアテンション部(テキストなどによる条件づけの箇所)が、(U-Net と切り離された)より小さな潜在空間で実行されるモデルですーーとくに ControlNet などは(U-Net 本体のエンコーダ部分を使わずに済むので)かなり小さくできそうですねーーそれら訓練用のスクリプトも公開されています:
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/stable_cascade/
- ・
- https://github.com/Stability-AI/StableCascade/tree/master/train
- ※5
- これらのモデルも、ComfyUI であつかえます:
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/video/
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/3d/
- ※6
- いずれのモデルも、拡散トランスフォーマ(DiT)の構造をベースにしています。Lumina-T2X はさらにフローベースの手法を採用し、音楽・画像・音声・映像・3Dを生成するマルチモーダルの試みが野心的です。PixArt も前の版(PixArt-α)は、Open-Sora の基盤になっていますがーーなお、Hunyuan-DiT はテンセント社、PixArt-Σ はファーウェイ社の支援がありそうですけど。
構成:SD モデルの構成
次が、潜在拡散モデル(LDM)の構成です。[※1][※2]
SD モデルの元になっているのが、この LDM です:[※3]
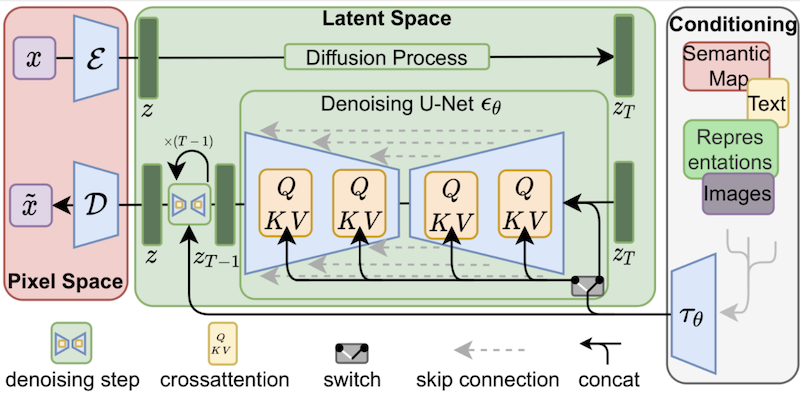
画像生成の訓練〜推定は、次の流れになります:
- ◯
- 画像を壊して(ランダムなノイズを加え)〜元に戻す(加えたノイズを取り除く)というやり方で、元の画像を生成できるよう訓練(拡散確率モデル)
- ◯
- 訓練と推定を、画像の特徴を抽出した小さな次元(潜在空間)で行うことで、より低い負荷で・より速く生成(部分空間拡散モデル/潜在拡散モデル)。
- ◯
- 生成時に条件(コンディショニング)を加えることで、生成する画像を、望む内容に近づけたりも(条件つき生成モデル)。

- ※1
- https://arxiv.org/abs/2112.10752
- ・
- https://arxiv.org/abs/2006.11239
- ※2
- 以降、画像生成の流れを追うなかで、この構成もあわせてみていきます。
- ※3
- とくに断りがないかぎり、ここでは「SD モデル」に SD 3 はふくめません(SD 3 はフローベースモデルです)。
遷移:基本:グラフ
以降、ComfyUI の基本の流れを追っていきます。
基本の流れは、SD モデルを使って、文章(テキスト)から画像(イメージ)を生成する、というものです:[※1]
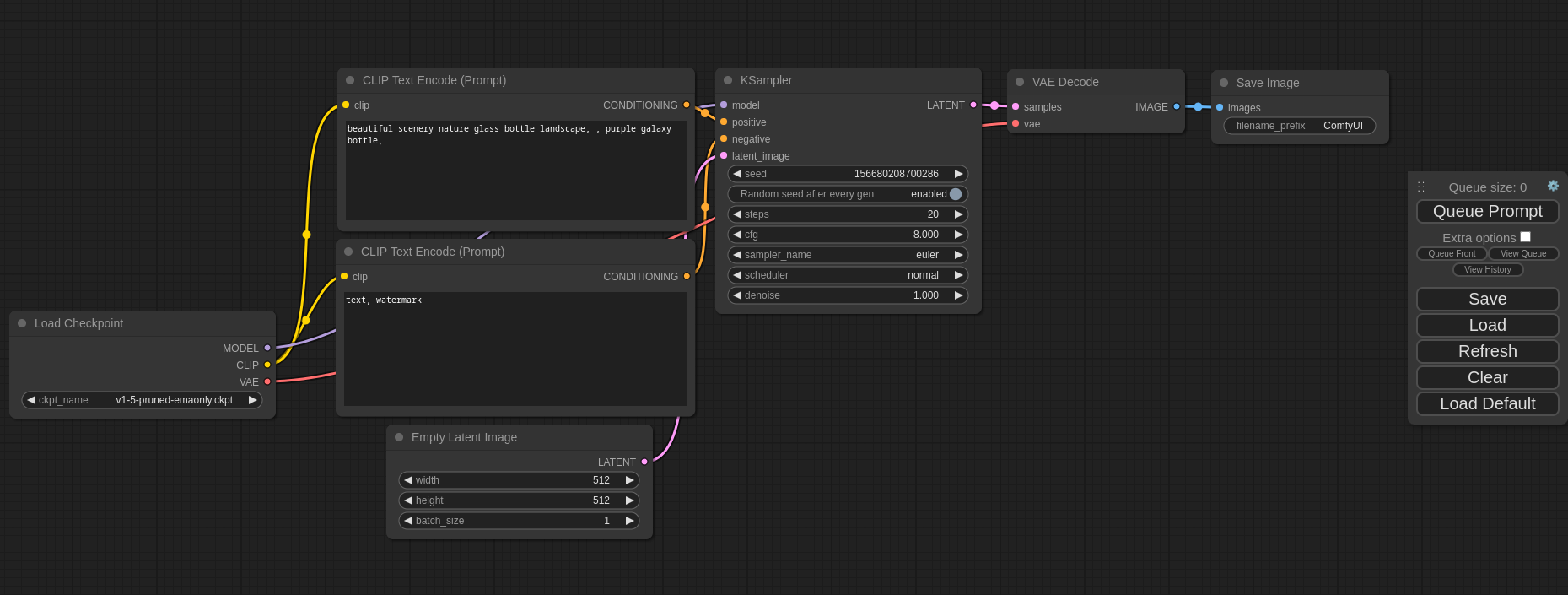
ここで使うノード群は、次の 6 種です:
- ・
- Load Checkpoint
- ・
- CLIP Text Encode (positive / negative)
- ・
- Empty Latent Image
- ・
- KSampler
- ・
- VAE Decode
- ・
- Preview Image / Save Image
以降の説明では、流れるデータも可視化してみます。[※2][※3]
あわせてフローのグラフと LDM の構成図も併記し、それぞれの要素が、グラフや構成図のどの箇所に当たるのかも示していきます。[※4][※5]
- ※1
- この基本の流れは、ComfyUI を起動したときの既定のものですーー作者によるチュートリアルは以下(ネコミミ版):
- ・
- https://comfyanonymous.github.io/ComfyUI_tutorial_vn/
- ※2
- こうすることで、あるていど静的なかたちで、全体を見通せる思うのでーー以降の図では、グラフに流れるデータ群を可視化するため、やり取りするデータ群のタイプ(型)を列挙していきます。ただし、それらがグローバルにあるというわけではありませんーーとはいえそれらのデータの受け渡しが、コピーかリファレンスか、あるいは(オブジェクト指向のように)データの隠蔽かは、けっきょく実装によりますーーComfyUI の作者も、厳密な関数型の挙動をさせるためというより、SD モデルの流れを理解したいというのが、データフロープログラミングのかたちを採用した動機のようですし。
- ※3
- たとえば U-Net のチェックポイントの受け渡しについても、(構造全体を渡すのではなく)モデルへのパッチという形で、そのコピーを使うようになっていますーーそして、渡されたデータしか使えない、という制約があるわけでもないようです(元のデータを、リファレンスから改変してしまうこともできるわけです):
- ・
- https://note.com/gcem156/n/n6a4d6973ed29
- ※4
- ただし、SD モデル(SDM)と LDM は、そもそも違うモデルです。LDM は検証モデルで、SDM はそれを発展させた実用モデルなのでーーじっさい、潜在空間のエンコーダ/デコーダは LDM (KL-VAE/VQ-VAE) / SDM (KL-VAE (F8)) 、潜在空間でのサンプラは LDM (DDPM) / SDM (DDIM) 、など、違いがあります。クロスアテンション部なども変わっていますーーただここでの説明は、そこまで細かいところには立ち入りません。なので基本的に、LDM の構成や遷移を前提に、SD モデルを説明していきます(なお拡散モデル一般について記すときは、そのように断りが入ります):
- ・
- https://henatips.com/page/47/
- ※5
- また、LDM の構成図は、もともと訓練もふくんだものです。なのでここで説明する生成だけの場合とは、すこし齟齬が出ます。
遷移:基本:ノード:Load Checkpoint
最初に、ローダが、SD モデルの<チェックポイント>を読み込みます。
チェックポイントは、ニューラルネットワーク(NN)のモデルを訓練したときの、最終の状態ですーーNN モデルの構造(グラフ)や、それらの変数の値群(パラメータ群)である、偏り(バイアス)や重み(ウェイト)がふくまれています。[→1][→2]
SD モデルも、NN モデルのひとつですーーこれに、読み込んだチェックポイントを適用することで、そのチェックポイントに沿った挙動をするようになります。
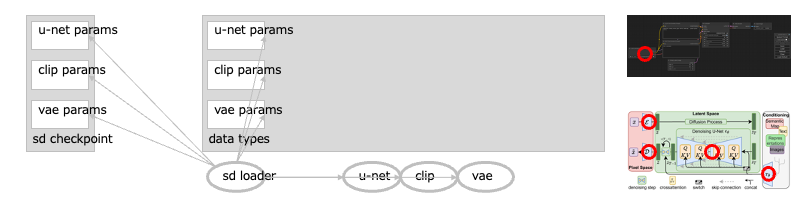
なお SD モデルは、3コの主要なモデルで構成されています。
それぞれ、VAE/U-Net/CLIP 、ですーーチェックポイントのパラメータ群も、このモデルごとに分かれています:[→3]
- ◯
- VAE
- ・
- VAE は、画像を低次元の<潜在空間>の要素に変換したり、その逆を行ったりするモデルです。[→4][→5][→6][後述]
- ◯
- MODEL (U-Net)
- ・
- U-Net は、ノイズを加えた画像から、元の画像を生成するよう訓練されたモデルですーーなお潜在拡散モデルでは、画像そのものではなく、<潜在空間の画像>が生成の対象になります。[後述]
- ◯
- CLIP
- ・
- CLIP は、テキストとイメージを統一してあつかえるよう訓練されたモデルですーーCLIP を通して、テキストを<ベクトルの集まり>(=埋め込み)に変換することで、イメージと比較できるようになります[後述]
- →1
- ニューラルネットワークは、プログラムで使う構造のひとつです。<データからパラメータを更新し、望みの動作をするよう調整できる>、のが特徴です。[※1]
- →2
- ニューラルネットワークの中身は、<計算>と<テンソル>ですーーテンソルは、行列の概念を一般化したものです(たとえばプログラムでテンソルを記述するときは、通常、カッコを何重にも重ねていきます:[[0.1, 0.2, 0.3, 0.4], [1.1, 1.2, 1.3, 1.4], ...])。とくに、0次元のテンソルをスカラ、1次元のテンソルをベクトル、2次元のテンソルをマトリクス(行列)、と呼んでいます。これらのテンソルにほどこすさまざまな処理が、計算です。計算の流れはツリー状に表され(計算グラフ)、その節(ノード)が計算に、枝(エッジ)がテンソルになります。そして、それらに格納される偏り(バイアス)や重み(ウェイト)が、パラメータ群になります。
- →3
- LDM の構成図では、赤丸をつけたところが、それぞれのパーツになります(VAE は左上(エンコーダ部分)と左下(デコーダ部分)、U-Net は中央、CLIP は右下)ーーもちろんこの構成図はあくまで模式図で、じっさいにこういう形状のパーツがあるわけではなく、すべての構造は、プログラム(コード)のなかで計算グラフとして記述されています。
- →4
- ここで<次元>は、<属性>のことです(表なら列が属性で、行がそれぞれの値になります)ーーたとえばヒトの身長と体重なら、属性の数は 2 コです。これはヒトの身長と体重を、2 次元のベクトルで表している、ともいえます。画像なら、属性は画素の位置だったりします。たとえば 2 × 2 ピクセルのモノクロ画像なら、左上から右下まで順に並べて [0, 1, 1, 0] などと表せます(白= 1 、黒= 1)。このとき、画像の属性の数は 4 コです。これは画像を、4 次元のベクトルで表している、ともいえますーーこのような大きさと向きをもつベクトルは、多次元の空間の一点を示すので、その対象は、多次元の空間に配置される 1 コの点、とみることもできますーーなので、たとえば 512 × 512 ピクセルのモノクロ画像は、262144 次元のベクトルで表されますが、これは 262144 次元の空間に配置される 1 コの点、ともいえます。[※2]
- →5
- 次元の<削減>は、(特徴を選択/抽出しつつ)対象の次元の数を減らすことです。次元が小さくなるため、計算が軽く速くなりますーー次元を削減することを「エンコード」、次元を復元することを「デコード」といいます。
- →6
- 次元の数を減らせば、当然、対象からそれだけの数の属性(特徴)が失われます。ただしうまく工夫することで(おもな属性を残したり/新しい属性に纏めたりすることで)、元の情報をうまく残すことができますーーこれを、<特徴の選択/抽出>といいます。
- ※1
- この構造のことを”AI”と言ったり、構造のパラメータを調整することを「訓練」/「学習」と言ったりするわけですねーー以前も”AI”と呼んでいたしくみがありましたが、そちらは還元論をベースにした代数系/離散的/記号的というべきもので、論理の構築がメインでした(帰納論理/演繹推論)。いまの”AI”は、全体論をベースにした解析系/連続的/統計的というべきもので、現象の再現がメインです(微分可能)。
- ※2
- カラー画像なら、画素ごとに RGB の 3 コの要素が必要になるので、さらに大きな次元になりますよね。
遷移:基本:ノード:CLIP Text Encode (positive / negative)
次に、テキストのエンコーダが画像への指示(プロンプト)を読み込みます。
プロンプトは、CLIP によって、ベクトルの集まりである<埋め込み>に変換されますーーこれで、テキストが潜在空間のイメージとどれくらい近いか/遠いかを、比較できるようになります。このときテキストエンコーダの挙動は、読み込んだチェックポイントの、CLIP パラメータ群に沿ったものになります。[→1][→2][→3][※1]
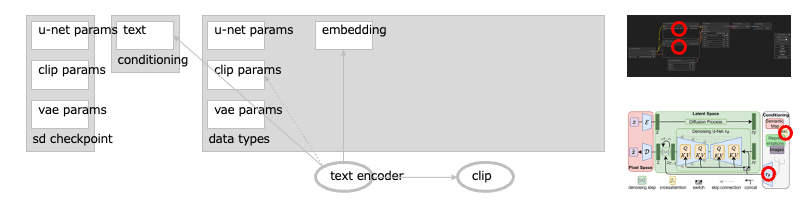
- →1
- テキストの<埋め込み>は、テキストを(ワン・ホットなどの)単純なベクトル群に変換したものではなく、その<特徴>が反映されたものですーーCLIP は、テキストに、イメージと比較できる特徴を与える NN モデルです。U-Net を通るイメージも多次元のベクトルなので、これでテキストとイメージを比較できるようになります(比較には内積を使います)ーー次はベクトルに変えた画像どうしの比較ですが、内積を使う例です:[※2]
- ・
- http://www.suri-joshi.jp/world/number/
- →2
- CLIP は、テキストとイメージを統一してあつかえる、マルチモーダルのモデルとして訓練されていますーーこのモデルの画期的なところは、訓練に使われていない、未知のカテゴリの画像も分類できることです(ゼロショット学習ーー大規模言語による学習が効いています)。なので、これを画像生成の条件づけに使えば、それまでに存在していないようなイメージでもテキストから描くことができる、ことになります。[※3]
- →3
- 埋め込みは、ただのベクトルの集まりでしかありません。なので、生成をコントロールするのにかならずしもテキストを使う必要はなく、適切に調整したベクトル群そのものを使うことで、いろいろなコントロールが可能になります(たとえば、埋め込みに変換済みのものを使用する(Textual Inversion)、など)。[後述]
- ※1
- SD モデルの CLIP パラメータ群はもともと固定されていますが、チューニングでそれらが変わっているものもありますーーそのようなチェックポイントを使った埋め込みは、SD モデルの標準 CLIP (OpenAI 社純正)+ CLIP の変更分のパラメータ+テキストの内容、の影響を受けることになります:
- ・
- https://blog.shikoan.com/diffusers_merge/
- ※2
- 言葉をベクトル化した特徴で有名なのは、意味の足し算/引き算ができる、といったものがありますよね(”king - man + woman = queen”、……)。
- ※3
- CLIP は、OpenAI 社が開発し〜無償で公開したものです。
遷移:基本:ノード:Empty Latent Image
ジェネレータが、生成する画像の元になる<潜在空間の空の画像>を作ります。
これは、ランダムなノイズを加えただけのものです。このとき、画像の縦・横のサイズと、いっぺんに何枚の画像を出力するか(バッチ数)も指定します。[※1]
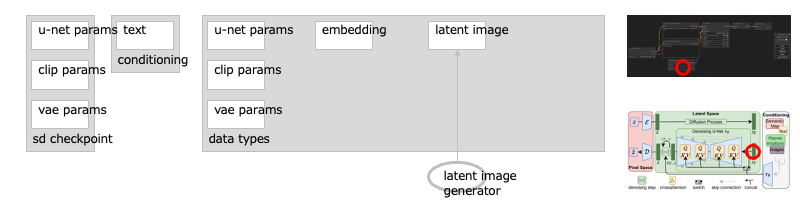
- ※1
- この画像を空でなく、任意のものにすれば、より多彩な生成ができるようになりますよね。[後述]
遷移:基本:ノード:KSampler
サンプラが、画像からノイズを取り除いていきます。[→1]
ノイズの除去は、U-Net を通して、潜在空間の画像に対して行われますーーこの過程は(U-Net の訓練時にノイズを加えた回数に依るので)、何度も繰り返すことになり時間がかかりますーーこれを短縮させる手法がいろいろあるので、通常は、そのどれか(サンプラ)を指定し、繰り返しの回数(ステップ)も指定します。[→2][→3][→4]
いっぽう生成途中の画像は、指定したテキストの埋め込みと比較されますーーそれが肯定的(ポジティブ)に指定されたテキストなら近づけるように、否定的(ネガティブ)に指定されたテキストなら遠ざけるように、画像は生成されますーーこの文章と画像の比較〜調整は、U-Net に設けられた複数の合流箇所(クロスアテンション部)で行われます。[→5][→6]
さらに U-Net の挙動は、読み込んだチェックポイントの U-Net パラメータ群に沿ったものになりますーーこれで生成画像が、指定したテキストに加え、チェックポイントの特性も併せもった内容になるわけですね。
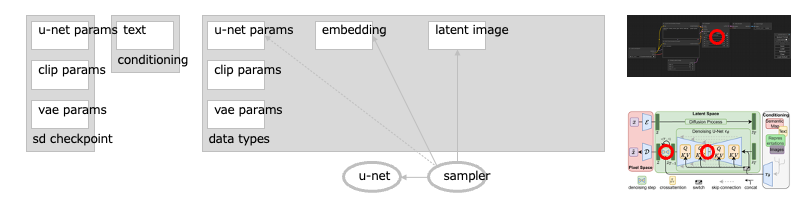
- →1
- U-Net が出力するのは、画像ではなく、<予測されるノイズ>の方です。この出力を元の画像から差し引くことで、生成画像になります(このようになっているのは、ノイズの予測の方が正規分布にしたがうからです)ーー次の記事では、かんたんな拡散モデルを実装しています:[※1]
- ・
- https://qiita.com/hotekagi/items/5afabf5945f125020eb1
- →2
- U-Net がノイズから元の画像を生成できるのは、ノイズ除去の<段階ごとに><最適な方向>を学習しているからですーー訓練のとき、ノイズは、画像にすこしずつ加えられます(たとえば 1000 回のノイズ添加)。U-Net はそれぞれの段階で、ノイズをすこしだけ取り除くことを学習します(たとえば 1000 回のノイズ除去)。これを繰り返すことで、元の鮮明な画像に到達させることができますーーこのようなことが単体のモデルで可能なのは、モデルに対し、画像自体の情報とともに、それがノイズ除去のどの段階にあるのか、という情報も与えられるためです(=系列情報の付加)ーーまたその途中で、画像の次元も削減されます。このような構造になっているため、画像のもつ特徴も、<段階ごとに>U-Net のパラメータ群に蓄積されます。
- →3
- 一般に、拡散モデルの訓練で画像に加えられるノイズは、正規分布にしたがうガウスノイズです(順拡散過程)。ここから偏りのある画像を生成することになるので、エントロビーが小さくなる方向(自由エネルギーが小さくならない、つまり散逸を最小にする経路)が、<最適な方向>になります(逆拡散過程)。その<最適な方向>を学ばせるための訓練ですがーー(VAE と同様に)対数周辺尤度の変分下限の最大化で学習でき、それを系列ごと独立に行える、というものです:[※2][※3][※4][※5][※後述]
- ・
- https://hillbig.github.io/WorkshopOT2023_diffusion_okanohara.pdf
- ・
- https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
- →4
- 一般に、拡散モデルで処理されるのは、多次元のベクトルをもつ画像です(これは多次元の空間で、その画像を示す一点ともいえます)。すると順拡散〜逆拡散過程は、この多次元空間における画像の、あるていど離散的なランダムウォークとみなすことができますーーこの過程を、連続的なブラウン運動として表すことで(ランジュバン方程式/確率微分方程式/SDE)、そのギザギザを取り去った、なめらかな軌跡として表すこともできるようになります(フォッカープランク方程式/偏微分方程式/PDE →常微分方程式/確率フロー ODE)。この場合、逆拡散過程は決定的になります(もちろん決定的といっても、その軌跡はあくまでマクロなもの(確率密度)ですが)ーーこういった SDE/ODE を使うことで、生成ステップを短縮させる、さまざまなサンプラを作ることができます(なお、DDPM や DDIM は、もともとの離散的なランダムウォークにもとづく<サンプラ>です)。[※6][※7][※8][※9]
- →5
- 指定したプロンプトに対し、画像をどれくらい近づけるかを指定するのが、ガイダンスです。とくに SD モデルでは、(事前の訓練を必要としない)分類器なしガイダンス(CFG)が使われています。これは、条件(プロンプト)を指定しない場合との差分を、この値で強めることで実現するものです。[※A][※B]
- →6
- LDM の構成図では、テキスト(などの)エンコーダから、U-Net 側に伸びる矢印の先端の”Q/K/V”が、クロスアテンション部ですーーここで、イメージは Q に入り、テキストは K/V に入ります。Q/K/V は、(データベース検索の比喩である)クエリ/キー/バリューの略ですが、実態は、系列を加味した加重和〜内積の計算です(ただし CLIP を使うテキストとイメージの比較では、ベクトルの大きさを加味しないコサイン類似度などを使います)ーーここを通ることで、イメージがテキストに沿ったものに近づいていきます。
- ※1
- SD モデルで「画像を生成する」というときは、つねにこの意味をふくんでいますーー「キリンの首」みたいな使い方ですね(端折るために「首を伸ばすために進化した」と言ったり)。
- ※2
- ここでは拡散モデルから VAE っぽい挙動をみていますが、むしろ、VAE の考え方から拡散モデルを構成することができますーー[1]VAE の潜在変数と観測変数を同じ次元にし、[2]エンコーダは、正規分布にしたがうガウスノイズを加えるだけにします。そして、[3]このモデルを系列(ノイズ除去の各段階)ごとにたくさんつないでいきます(前の観測変数を、次の潜在変数にする)ーーこれが、拡散モデル(DDPM)になります。つまり拡散モデルは、<階層化された VAE>とみることができるわけです。このように構成した生成モデルは、エンコーダの訓練が不要で、系列ごと独立に訓練〜推定させることができる(マルコフ性)、という特徴をもちますーーなんという効率性と安定性……:
- ・
- https://www.oreilly.co.jp//books/9784814400591/
- ※3
- とはいえ、これだけ多様で鮮明な生成ができる、というのはやっぱり不思議ですよねーーひとつは、たゆまぬ手法の工夫によるものといえますーー生成モデルは、高次元空間にある、おおくの対象からなる確率分布を模倣することで、ある対象を生成できるようになります。ただしその確率分布の地形は、凹凸が複雑なのに(多峰性)、低次元に偏在しています(多様体仮説)……谷に止まらないためには峰を越えないといけないのに、飛びすぎるとほぼなにもない空間に投げ出されてしまったり。特定の場所に執着しすぎても(モード崩壊)、適応しすぎてもいけなかったり(過学習)。そして地形を把握するには、暗闇のなかで動き回るしかないという……なのでとりあえず、暗闇で動けるようマルコフ連鎖モンテカルロ法を導入し(エネルギーベースモデル)、多峰性に応ずるためにスコア(対数尤度の勾配)を指針とするランジュバン・モンテカルロ法を導入し(スコアベースモデル)、スコアの推定と/過学習を避けるために、カーネル密度推定を導入し/ガウスノイズを加え(摂動)(デノイジングスコアマッチング)、多様体仮説に応ずるためにガウスノイズを広げ縮めていく(撹乱)(ノイズ条件つきスコアネットワーク)ーーこのあたりで、多様で鮮明な生成ができるようになったようですがーーただ、いまはこれと数学上で等価な、デノイジング拡散確率モデルが台頭し、生成時間を短縮させるさまざまなサンプラが開発されている、という状況ですよね(なお拡散モデルは、(敵対的生成ネットワークと違って)最尤推定を採用し、(変分オートエンコーダと違って)生成モデルのみの学習に専念するので、モード崩壊を起こしにくい、とも):
- ・
- https://www.iwanami.co.jp/book/b619864.html
- ※4
- ただ<確率分布だからデータから丸コピしない>かというと、それは保証されないわけですーー理屈のうえでは、すべての画像は多次元空間の一点にあるので、その一点が合致すれば、元画像の完全な複製が生成されます。もちろん、高次元/高精度のなかで合致する確率は(訓練に使う元画像の数が相応に大きいかぎり)とても低いわけですがーーとはいえ現実には、(モード崩壊や過学習が起こりにくいとされる)拡散モデルでも、生成画像がその近くに行くことはあるようです:
- ・
- https://zenn.dev/shinya7y/articles/6442b1350418ef
- ※5
- そもそも、このような複雑な問題に対応できるよう訓練できる、というのも不思議ですーーたしかにニューラルネットワーク(NN)は、あらゆる計算ができ(チューリング完全ーー活性化関数が段階の場合)、あらゆる関数を近似できる(普遍近似定理ーー活性化関数が非線形の場合)、という性質をもっています。そして近似するための誤差を計算できるかぎり(損失関数が微分可能なかぎり)、そのかたちに寄せていくことができます(誤差逆伝播法)ーーとはいえそれだけなら、3 層の NN で十分で、しかもパラメータの数が増えるほど過学習になるはずでした。でも現実には、層がたくさんあり/パラメータも大きい深層 NN が、いろいろな問題に対応できていますーーどうもその方が、不連続な関数の混在に適応できたり、小さなニューラルネットの集合として機能するから、のようですけど:
- ・
- https://www.iwanami.co.jp/book/b570597.html
- ※6
- 次に、SDE 系/ODE 系のサンプラがまとめてあります:
- ・
- https://henatips.com/page/58/
- ※7
- これらのサンプラは”k-diffusion”のコードにまとめられていて、(ComfyUI ふくめ)拡散モデルアプリの多くが、このコードを使っています:
- ・
- https://github.com/crowsonkb/k-diffusion
- ※8
- ステップごとに取り除くノイズ量を調整することを、ノイズスケジューリングといいますーーComfyUI では、これを行うノイズスケジューラが、サンプラと切り離して実装されています:
- ・
- https://github.com/comfyanonymous/ComfyUI/discussions/227
- ※9
- ちなみに CM/LCM は、確率フロー ODE で、解の軌道が一貫するという前提からモデル化したものです。
- ※A
- この<条件を指定しない>というところを、<べつの条件を指定する>ことに置き換えると、ネガティブプロンプトになりますーーつまり、ネガティブプロンプトを指定した仮の生成画像が基準になり、そこからどれだけ離れるかが、ガイダンスの大きさで決まる、というしくみですね。
- ※B
- さらに CFG の動作を利用して、学習したプロンプトと逆の方向に誘導する手法が、ESD です(これを符号反転させれば、むしろ強調する方向にも誘導できたり)ーーこの ESD の手法を使って、LoRA として学習させたモデルが LECO です。
遷移:基本:ノード:VAE Decode
画像のデコーダ(VAE)が、じっさいの画像に変換します。
この<潜在空間の画像>から<画素の集まり>への変換で、ヒトが認識できる画像になります。このとき VAE デコーダの挙動は、読み込んだチェックポイントの、VAE パラメータ群に沿ったものになります。[→1][→2][→3][→4]
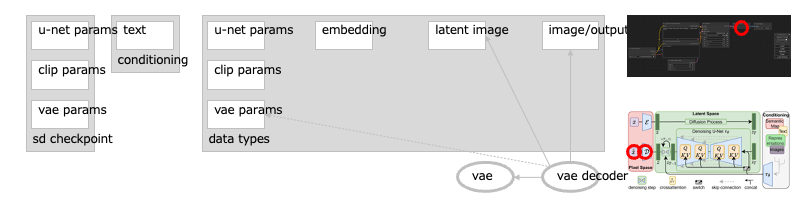
- →1
- VAE でエンコードされた画像の特徴群(の確率分布)は、低次元の空間に配置されることになります。これを<潜在空間>といいますーー潜在拡散モデルでは、VAE が作った潜在空間のなかで、U-Net が画像を生成していきます(逆拡散過程のとき)。このような構成では、VAE がおもに画像の体裁(外観)をあつかい、U-Net がおもに画像の内容(意味)をあつかう、ともいえます。[※1]
- →2
- 次元削減の手法では、線形なら主成分分析(PCA)、非線形ならオートエンコーダ(AE)といったものがシンプルなことで知られています。シンプルでも非線形な AE を使えば、画像など複雑な対象でも、特徴を抽出できます。ただ AE は、特徴を潜在空間の一点に集約し、配置もバラバラにしてしまうので、生成には向きませんーーいっぽう変分オートエンコーダ(VAE)は、特徴を確率分布にしてなめらかにし、それらの分布も、潜在空間の原点を中心に配置します。この工夫があるので、U-Net から出力された<潜在空間の画像>を、素直に、通常の画像に変換できます:
- ・
- https://keiorogiken.wordpress.com/2021/12/03/...
- →3
- 潜在空間は、<潜在変数>を前提にした空間ですーー潜在変数は、みえない(かくれた)変数です。この潜在変数が、じっさいにみえる変数である<観測変数>に、影響を与えると仮定しますーー統計処理でも機械学習でも、こういった潜在変数を使って、モデルを調整していくことがあります。
- →4
- 変分オートエンコーダ(VAE)は、変分ベイズ推定を使うオートエンコーダです。この推定で、潜在変数を使いますーーベイズ推定は、事前の確率分布(と尤度と周辺尤度)から、事後の確率分布を推定する手法です。「変分」は変分法のことで、汎関数/高階関数(変数が関数である関数)の最小化や最大化を試みる手法ですーーこのとき、潜在変数を原因〜観測変数を結果とする確率分布を求めたいのですが、難しいので、それに近似すると仮定した潜在変数の確率分布を求めます。VAE は、対数周辺尤度の変分下限(汎関数)を最大化するよう学習することで、このふたつの確率分布の<距離>(KL ダイバージェンス/KL 情報量)を、最小化しようとするものです。[※2][※3][※4][※5]
- ※1
- U-Net と VAE はペアなので、VAE の選択を誤ると、U-Net からの出力が異常になったりしますよね(色がくすんだり、意味不明な描画になったり)。
- ※2
- あの最速降下問題(どんなカタチのすべり台だと、いちばん速く地面に到達できるか)でよく使われる手法も、変分法ですーー変分法が整理されるのは、この問題が解かれたもっとあとの時代ですが:
- ・
- https://hooktail.sub.jp/mathInPhys/brachisto/
- ※3
- KL ダイバージェンスを<距離>と言ったりしますが、厳密には違います(対称性を満たしていない)ーー確率分布間の距離を測るのに、たとえば、最適輸送の特殊な場合であるワッサースタイン距離/計量は、じっさいに距離の公理を満たします(反面、計算量は増えます)。
- ※4
- VAE の技術は画像生成だけでなく、音声生成にも利用されています(VITS など)。また強化学習では、マルコフ決定過程を前提にしているものが多くありますが、これも(VAE が採用している)ベイズ推定と密接に関係しています。
- ※5
- 変分ベイズ推定で言及される<自由エネルギー>(対数周辺尤度の符号反転)は、統計力学との関連でそう呼んでいるものです。また<変分自由エネルギー>(対数周辺尤度の変分下限の符号反転)は、脳神経学でフリストン氏などが使っていたりします(自由エネルギー原理など)。
遷移:基本:ノード:Preview Image / Save Image
最後に、画像のマネージャが、画像を表示/保存します。
これは潜在拡散の過程とは関係なく、通常のイメージ操作になります:
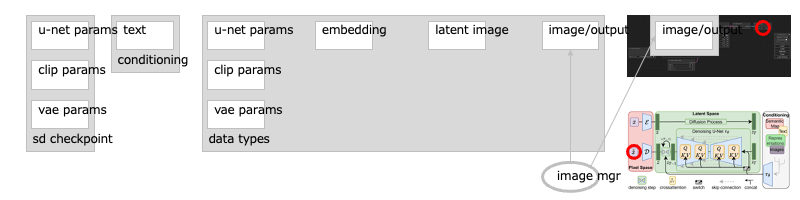
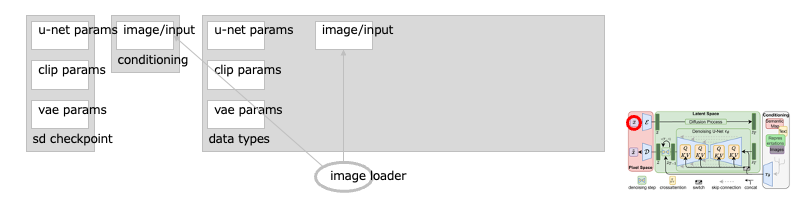
遷移:補足:ノード:Load Image / VAE Encode
なお、潜在空間の元画像を、任意の画像の特徴に変えることもできます:[※1]
- ・
- Load Image
- ・
- VAE Encode
これにより、元画像に似た画像を生成できるようになりますーーこの場合は、通常の画像をローダで読み込み:
画像のエンコーダ(VAE)で、潜在空間の画像に変換します:
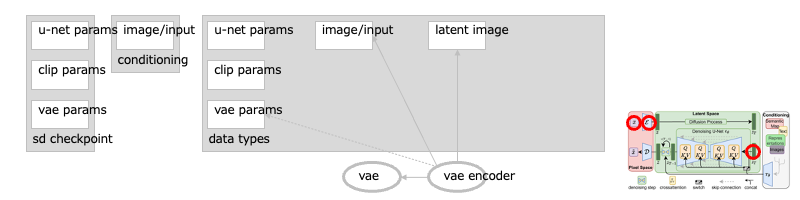
また、元画像にマスクしたものを使うと、その抜けた箇所を補うような画像を生成することもできます:[※2]
- ・
- VAE Encode for Inpaint
- ※1
- この生成を、”image to image”や”i2i”と言ったりもしますよね(対比として、通常のプロンプトによる生成を、”text to image”や”t2i”と言ったり:
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/img2img/
- ※2
- https://comfyanonymous.github.io/ComfyUI_examples/inpaint/
遷移:補足:ノード:Upscale Latent / Image Upscale with Model/ Upscale Model Loader
画像を高詳細にしたいときは、アップスケーラを使います。
潜在空間向け/通常空間向けがあるので、サンプラの出力につなげます(通常空間向けなら VAE のデコーダも使います):
- ・
- Upscale Latent …… アップスケーラ(潜在空間向け)[※1]
- ・
- Image Upscale with Model …… アップスケーラ:モデル利用(通常空間向け)[※2]
- ・
- Upscale Model Loader …… モデルのローダ:アップスケール用(通常空間向け)
- ※1
- これはたんに、画像のサイズを潜在空間で変えて、再度サンプラを通すだけですーー基本は i2i なので、t2i による指示が必要になります:
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/2_pass_txt2img/
- ※2
- 通常空間で画像を高詳細化するため、専用に訓練されたモデルを使います(ESRGAN, ...)ーーこの手法では t2i は不要なので、その場で生成したものではない通常の画像も、高詳細化できます(この場合は、たんにローダ(Load Image)で読み込んだ画像を、アップスケーラに通すだけです):
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/upscale_models/
遷移:補足:ノード:Conditioning Set Area / Conditioning Combine
条件(プロンプトなど)を、画像の特定の区画に適用させることもできます。
これらのノードは、テキストエンコーダの出力など、コンディショニングが流れるリンクにつなぎます:[※1]
- ・
- Conditioning Set Area …… 条件(プロンプトなど)の適用区画を指定する
- ・
- Conditioning Combine …… 複数の条件(プロンプトなど)をミックスする
- ※1
- https://comfyanonymous.github.io/ComfyUI_examples/area_composition/
構成:拡張:SD モデルのマージャ
複数の SD モデルから、新しい SD モデルを作ることができます。[→1]
複数の U-Net のチェックポイントを合成(マージ)し、新しい U-Net のチェックポイントを作ります(VAE/CLIP は変換しませんが、どのモデルのものを使うかは指定します)ーーこのマージは、メモリ上で実行されます:[※1]
- ・
- Model Merge Simple …… U-Net のパラメータ群を合成:割合を一括指定
- ・
- Model Merge Blocks …… U-Net のパラメータ群を合成:割合を個別指定(エンコーダ部分/中間/デコーダ部分)[※2]
- ・
- Medel Merge Subtract / Model Merge Add …… U-Net のパラメータ群を合成:差分の追加[※3]
マージしたチェックポイントは、次のノードから保存できます:
- ・
- Checkpoint Save …… チェックポイントを保存する[※4]
- →1
- ニューラルネットワークの学習は非線形なので、訓練後のモデルのパラメータ群も、それに沿ったものになっていますーーそれを、足し算や掛け算のような単純な係数補間でなぜ調合できるかというと、ファインチューニングしたモデルの重みが線形だから、との主張から来ているようです:[※5][※6]
- ・
- https://arxiv.org/abs/2109.01903
- ・
- https://arxiv.org/abs/2208.05592
- ・
- https://arxiv.org/abs/2212.04089
- ※1
- マージのパラメータの精度を大きくしておきたいなら、起動時に高精度(fp32)になるよう指定しておきます(ComfyUI は、既定で中精度(fp16)で稼働します):
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/model_merging/
- ※2
- いわゆる層別マージの簡易版ですーーU-Net は、大きくエンコーダ部分/中間/デコーダ部分に分かれています(LDM の構成図でいえば、中央のくびれているところが中間です)。これらの割合を個別に指定して、マージします。
- ※3
- いわゆる (A - B) + C のマージですーーA が B の派生モデルのとき、A の差分(特徴)だけを抜き出し、C に合成します。
- ※4
- 保存が必要ならこのノードを最後につけるか、通常は無効にしておき〜保存するときに有効にします。
- ※5
- 日本で SD モデルのマージ(層別マージふくむ)が注目され出したのは、Kohya S 氏の次の記事からではないでしょうか(このスクリプトのもとになった手法は、WiSE-FT のようですが):
- ・
- https://note.com/kohya_ss/n/n9a485a066d5b
- ※6
- すこし怪しげで錬金術ともいわれていたマージの技法ですが、デビッド・ハー氏の Sakana AI 社(由来)が、これに進化的計算を適用して成果を上げたようですーー着眼点が独特というか、すごいですね(なお、ハー氏も、これを開発した(論文の筆頭である)秋葉氏も、一時 Stability AI 社に在籍していました……):
- ・
- https://sakana.ai/evolutionary-model-merge-jp/
構成:拡張:SD モデルのチューナ/コンディショナ
以降、チューナとコンディショナをあつかうノード群をみていきます。[※1]
チューナは、SD モデルそのものの挙動を変えることができるモデルです。挙動が変われば、生成される画像も変わります:
- ・
- DreamBooth
- ・
- LoRA (LoRA Loader)
- ・
- HyperNetwork (HyperNetwork Loader)
- ・
- IP-Adapter (Load IPAdapter)
- ・
- AnimateDiff (AnimateDiff Loader)
コンディショナは、SD モデルに与える、条件づけを変えることができます:
- ・
- Textual Inversion
- ・
- ControlNet (Load ControlNet Model, Apply ControlNet )
テキストだけでは難しい表現も、これらのノード群で出力できるようになるわけですね。
- ※1
- https://comfyanonymous.github.io/ComfyUI_examples/
遷移:拡張:SD モデルのチューナ:DreamBooth
DreamBooth は、U-Net 全体の挙動を変える手法です。
拡散モデルでは、下流工程のもっとも基本となる、ファインチューニングの手法といえます。[→1][→2]
なおチューニングしたモデル自体が、SD モデルと同じ形式になりますーーなので、これ専用のノードというのは、とくにありません。[※1]
- →1
- 上流工程で事前訓練されたモデル(基盤モデルふくむ)を、下流工程でチューニングする手法には、さまざまなものがありますーーそのなかでも、モデル自体のパラメータ群を変えるファインチューニングは、もっとも基本になるものです。
- →2
- DreamBooth では、上位分類(クラス)とその下位分類/実体(インスタンス)というかたちで、拡散モデルに新しい概念を獲得させますーーインスタンスを指示するプロンプトには、(CLIP が学習していないだろう)特別な言葉(トークン)を割り当てます。このとき、それぞれの画像を出力するよう訓練したモデル(クラスのトークンのみのモデルと、クラスのトークン+インスタンスのトークンのモデル)のパラメータ群の差分が、新しいモデルに適用されます:[※2][※3]
- ・
- https://arxiv.org/abs/2208.12242
- ・
- https://note.com/myelin_3/n/ne323335454a3
- ※1
- この手法で得られるチェックポイントは、学習元の SD モデルのチェックポイントとほぼ同じサイズになりますーー使い勝手がよくないので、より軽量のアダプタ型のチューニング手法(LoRA, ... )が台頭することになりましたが。
- ※2
- インスタンスのトークンに、あるていど汎用の言葉を割り当ててもそれなりに学習はするようですが、訓練時間が長期化し/モデルも不安定になるようです。
- ※3
- クラス〜インスタンスというかたちではなく、たんに特別なトークンのみで学習させる手法もありますーーいま SD モデルでよく使われているアダプタ型のチューニング手法(sd-scripts の LoRA)では、このかたちがむしろ一般的になってますね(この場合は、学習させる画像と、その画像と対になるキャプション(タグ群をふくむ)で生成されるだろう画像の差分が、アダプタのパラメータ群になる、というわけです)。
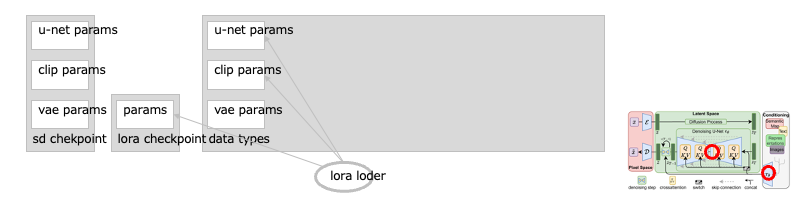
遷移:拡張:SD モデルのチューナ:LoRA (LoRA Loader)
LoRA は、U-Net のクロスアテンション部などの挙動を変えます。[※1][※2]
次元を削減できるアダプタを作り、このアダプタを訓練します。これが U-Net の本流と足し合わされることで、全体の挙動が変わります。さらにオプションで、CLIP のパラメータ群も、訓練の対象にしたりします。[→1]
なのでこのノードは、U-Net パラメータ群と CLIP パラメータ群のパッチになりますーーこの2箇所から流れるリンクにつなぐことになります。[※3]
- →1
- LoRAは、次元を削減する一手法の特異値分解(SVD)から発想されたチューナですーーアダプタとなる 2 コの行列(SVD では 3 コ)は、それぞれもとの行列の行数/列数をもっていますが、次元の数は間引くよう調整します(この間引いた数を「ランク」といいます)。それらの行列の積をとり〜もとの行列との和をとるだけで、もとの行列のパラメータ群を近似できる、という手法ですーーこのため、学習時は GPU のメモリや訓練時間を減らせ、アダプタのチェックポイントの容量もはるかに小さくできます:[※3][※4][※5][※6]
- ・
- https://arxiv.org/abs/2106.09685
- ・
- https://xrg.hatenablog.com/entry/2023/06/12/210059
- ※1
- SD モデル向けの LoRA 作成でほぼ標準となっているのが、Kohya S 氏の”sd-scripts”ですーーなお、オプションで CLIP(テキストエンコーダ)のパラメータ群も学習の対象としたのは、学習元のデータが少ない場合に有効と判断したからのようですね:
- ・
- https://github.com/kohya-ss
- ・
- https://github.com/kohya-ss/sd-scripts/blob/main/docs/fine_tune_README_ja.md
- ※2
- また sd-scripts は、使用する手法がモジュール化されています(--network_module)ーーこのモジュールは第三者も作ることもでき、代表的なものに KohakuBlueleaf 氏が開発する”LyCORIS”シリーズがあります。このシリーズで、LoRA のさまざまな派生手法が使えます(このうち一部は、sd-scripts 本体のモジュールでも使えます):DyLoRA, DoRA, LoHa, LoKr, LoCon, ...:
- ・
- https://github.com/KohakuBlueleaf/LyCORIS
- ・
- https://github.com/KohakuBlueleaf/LyCORIS/blob/main/docs/Algo-List.md
- ※3
- LoRA のローダには、U-Net/CLIP 、それぞれの強度を調整するスライダが設けられています:
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/lora/
- ※4
- 次は SVD による次元削減ですが、その効果がよく分かる実験です:
- ・
- https://thinkit.co.jp/article/16884
- ※5
- 当初は LoRA も、SD モデルのチェックポイントにマージする、という形で使われていましたーーいまはリアルタイムにマージされるので、そういう手間は不要ですね。
- ※6
- 最初の LoRA の論文は、大規模言語モデルのチューニングに提案されたものですーーなぜそれほど大きなモデルを、これだけ低いランクの行列で調整できると考えたかというとーーその論文では、モデルのパラメータ群が(学習後だけでなく学習中も)より低い次元に偏在しているからだとしていますがーーじっさい画像でもこれだけ LoRA が成功しているので、それなりに普遍性のある現象なのかもしれませんね。
遷移:拡張:SD モデルのチューナ:HyperNetwork (HyperNetwork Loader)
HyperNetwork は、クロスアテンション部の挙動を変えるために、専用の NN モデルを訓練し、その出力をクロスアテンション部と合成します。[※1]
なのでこのノードは、U-Net パラメータ群のパッチになり、そこから流れるリンクにつなぎぐことになります。[※2]
- ※1
- もとは、ドーガン氏による Anlatan 社の独自技術です。2022 年 10 月に NovelAI サービスから、生成モデルとともにソースコードも流出したので、このチューナもいろいろな画像生成アプリに実装されてきたわけですが。
- ※2
- https://comfyanonymous.github.io/ComfyUI_examples/hypernetworks/
遷移:拡張:SD モデルのチューナ:IP-Adapter (Load IPAdapter)
IP-Adapter は、U-Net に<訓練可能な画像専用の>クロスアテンション部をもう 1 コ追加することで、参照する画像の特徴を(イメージエンコーダや専用のモデルなどから)とらえて生成します。[※1]
なのでこのノードは、U-Net パラメータ群のパッチになり、そこから流れるリンクにつなぎぐことになります。[※2]
- ※1
- https://arxiv.org/abs/2308.06721
- ・
- https://huggingface.co/h94/IP-Adapter
- ・
- https://huggingface.co/h94/IP-Adapter-FaceID
- ※2
- 使用時は、モデルと組み合わせるイメージエンコーダを適切に選ぶ必要がありますーーとくに FaceID のモデルの場合、イメージエンコーダの有無や LoRA の組み合わせが、バージョンによって異なります。
- ・
- https://github.com/cubiq/ComfyUI_IPAdapter_plus
遷移:拡張:SD モデルのチューナ:AnimateDiff (AnimateDiff Loader)
AnimateDiff は、テキストのみで映像を作ることができる手法です。
U-Net のそれぞれの層(レイヤ)に、モーションのためのモジュール群を挿入し、複数枚の画像(フレーム)間で訓練することで、あまり違和感を感じないレベルの映像生成を可能にしています。[※1]
なのでこのノードは、U-Net パラメータ群のパッチになり、そこから流れるリンクにつなぎぐことになります:[※2]
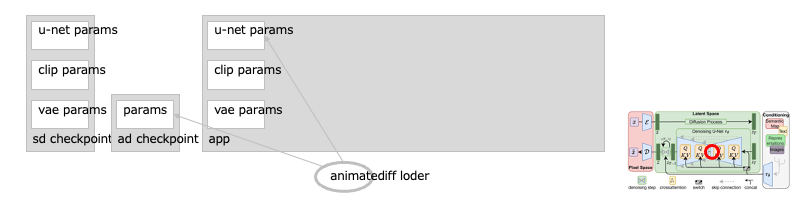
アニメーションを生成するので、バッチには、映像のフレーム分の枚数を指定します:
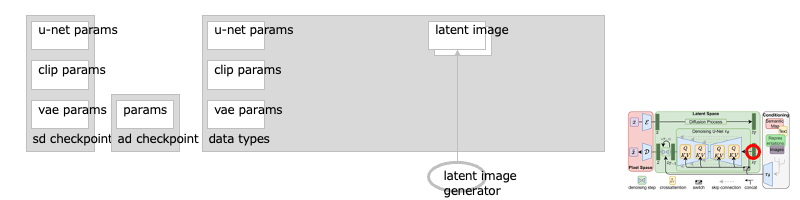
また、生成された映像のフレーム群を、映像形式(GIF)に変換してプレビューできるノードもあります。
- ※1
- https://arxiv.org/abs/2307.04725
- ※2
- https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
遷移:拡張:SD モデルのコンディショナ:Textual Inversion
Textual Inversion は、テキストエンコーダが出力する<埋め込み>そのものを、個別に提供するものです。
これはテキストエンコーダ内で、埋め込みのチェックポイントのファイル名を指定することで、適用します(ファイルの拡張子は省くことができます)。[→1]
- →1
- テキスト中の埋め込みの順序を変えることで、効果も変わりますーーこれ専用のノードがないのは、そのような性質があるためです:
- ・
- https://comfyanonymous.github.io/ComfyUI_examples/textual_inversion_embeddings/
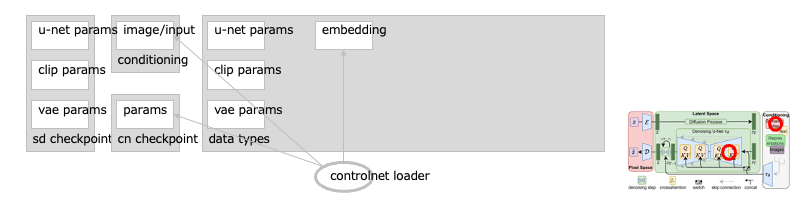
遷移:拡張:SD モデルのコンディショナ:ControlNet (Load ControlNet Model, Apply ControlNet )
ControlNet は、(テキストではなく)イメージで、全体の構図や人物の姿勢などを調整する手法です。
U-Net の前半と中央(エンコーダ部分)を複製したニューラルネットワークを使い、条件づけの画像と文章を入力に、生成すべき画像を出力にして、訓練します。こうすることで、さまざまな指示に使えるモデルを作れるようになります(輪郭線用、落書き用、ポーズ用、……)。[※1][※2][※3]
これは画像認識(物体検出やセグメンテーションなど)の流れを汲む技術ですが、画像生成では、このように条件づけ(コンディショニング)に応用されています。
なのでこのノードは、コンディショニングが流れるリンクにつなぎます(通常は、テキストエンコーダにつなぐことになります)ーーただし、イメージによる条件づけは、U-Net の(クロスアテンション部ではなく)スキップコネクションの方に合流します(そのように訓練されているので)ーーこのあたりはすこし混乱するかもしれません……[※4][※5]
- ※1
- https://arxiv.org/abs/2302.05543
- ※2
- 開発者自身による、かんたんな訓練のサンプルです:
- ・
- https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md
- ※3
- 開発者の Lvmin Zhang (lllyasviel) 氏はもともと、輪郭から自動彩色するアプリ(”Style2Paints”)を提供していました(アニメ好きみたいで、GitHubのアカウントにもそれが表れてますよね)ーーその技術を SD モデル向けに拡張したのが、ControlNet といえます。なお同氏は、SD で透明レイヤを可能にする LayerDiffusion 、画像に光線の分布を合成する IC-Light 、言語モデルで画像生成の独自コードを生成する Omost 、なども開発しています。画像生成のアプリでも、生成サービス”Midjourney”に寄せたシンプルな UI をもつもの(”Fooocus”)、生成アプリ”AUTOMATIC1111/SD web UI”の UI をそのままに高速化したもの(”Forge”)、も提供しています(なお Forge には、comfyanonymous 氏からクレームが入ったりして大変そうです):
- ・
- https://lllyasviel.github.io/Style2PaintsResearch/lvmin
- ・
- https://lllyasviel.github.io/Style2PaintsResearch/
- ・
- https://github.com/lllyasviel/LayerDiffuse_DiffusersCLI
- ・
- https://github.com/lllyasviel/IC-Light
- ・
- https://github.com/lllyasviel/Omost
- ・
- https://github.com/lllyasviel/Fooocus
- ・
- https://github.com/lllyasviel/stable-diffusion-webui-forge
- ※4
- https://comfyanonymous.github.io/ComfyUI_examples/controlnet/
- ※5
- スキップコネクションは、U-Net で画像を生成するとき、エンコーダ部分(画像の次元を削減する)からデコーダ部分(画像の次元を復元する)に、情報を渡す箇所ですーー次元の削減は詳細な情報が失われる過程なので(その代わり重要な情報=特徴を残します)、次元を復元するとき、元の情報を活用するために使われています。
参照:書籍/記事/動画
以下、関連の情報です。
次は、拡散モデルの解説と実装、またそれらの基礎を提供する、非線形・非平衡物理の解説ですーー日本語でこれだけていねいな書籍があるというのは、心づよいですね:
- ・
- 非平衡統計力学[沙川貴大][※1]
- ・
- 拡散モデル[岡野原大輔][※2]
- ・
- ゼロから作る Deep Learning ーー生成モデル編[斎藤康毅][※3]
次は、上記の解説や実装への橋渡しをしてくれる、分かりやすい記事と動画です:
- ・
- ゆらぎの定理[松本拓巳(ヨビノリ)][※4]
- ・
- 何だって、したしむ[かくびー][※5]
- ・
- 人工知能と親しくなるブログ[hoshikat][※6]
ComfyUI の解説は、次が日本語の総本山でしょうか:
- ・
- ComfyUI 解説[?][※7]
- ※1
- 付録に、ランジュバン方程式〜フォッカープランク方程式への伊藤の公式の適用や、ゆらぎの定理証明もあります。
- ※2
- エネルギーベースモデルから、スコアベースモデルと拡散確率モデルを展開しています(エネルギーベースモデルは汎用的に記述できるので、ルカン氏がこのような思惑でJEPAを進めていたり、岡野氏もこのような構造を考えていたり)[※8]。
- ※3
- VAE から拡散モデルを導く過程を、くわしく解説していますーーシリーズの以前の内容にくらべると数式が中心ですが、動かせるコードがしっかりある、という点は変わりません。
- ※4
- ゆらぎの定理からのジャルジンスキー等式導出があります。
- ※5
- SD モデルの具体的な例をまじえた「拡散モデル」本の解説です。
- ※6
- 拡散モデルの構造を、やさしい文章と画像で解説しています。
- ※7
- それぞれのノードのはたらきが、おそろしいほどに詳しく検証されています。
- ※8
- 以下、この記事で挙げた、生成モデル群の位置づけです(「拡散モデル」本、その他の情報から)ーーすべて、連続的なデータ(音声や画像など)をあつかうモデルで、学習面からの分類になりますーー構造面では、離散的なデータ(言語など)をあつかう生成モデルから、トランスフォーマを流用する動きが活発なので、こちらはかなり融合してますね:
- ・
- > 暗黙的生成モデル
- ・
- >> 敵対的生成モデル/敵対的生成ネットワーク/GAN
- ・
- > 尤度ベースモデル
- ・
- >> エネルギーベースモデル/EBM
- ・
- >> 拡散モデル/DM
- ・
- >>> スコアベースモデル/SBM
- ・
- >>>> デノイジングスコアマッチング/DSM
- ・
- >>>>> ノイズ条件つきスコアネットワーク/NCSN
- ・
- >>> デノイジング拡散確率モデル/DDPM
- ・
- >>>> 部分空間拡散モデル/潜在拡散モデル/LDM > SD 1 - 2, SDXL 1
- ・
- >> 一貫性モデル/CM
- ・
- >>> 潜在一貫性モデル/LCM
- ・
- >> フローベースモデル
- ・
- >>> 正規化フロー/NF
- ・
- >>>> 連続正規化フロー/CNF
- ・
- >>>>> フローマッチング/FM > SD 3
- ・
- >> 変分オートエンコーダ/VAE