

ComfyUI の基本の使い方から、画像生成の概要をみていきます。
関連
- ◯
- ComfyUI で画像生成 〜 なぜそこにつなぐのか:ComfyUI, Stable Diffusion[※1]
- ◯
- ComfyUI を、クラウドのコンテナに設置する:ComfyUI, Docker, GCP[※2]
- ※1
- 画像生成のより詳しい流れはこちら。
- ※2
- アプリの設置のしかたはこちら。
導入
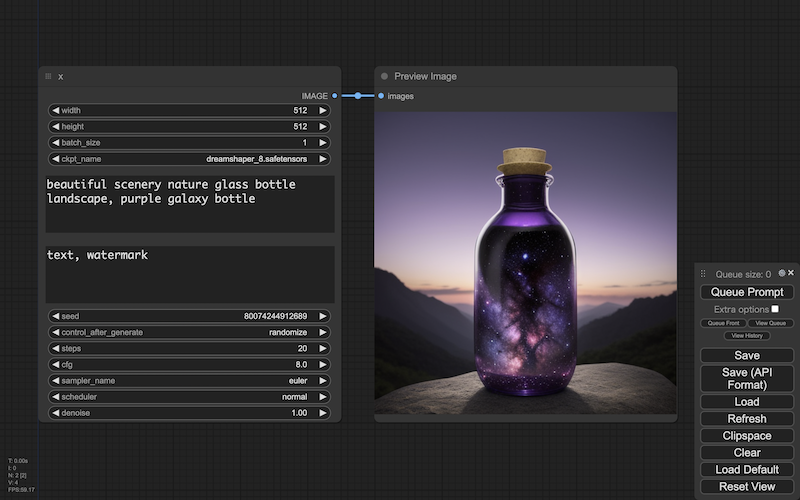
画像生成アプリを使うと、言葉から画像を生成することができます。
この生成の概要を、ここでは ComfyUI というアプリを使用しながら、みていきたいと思います。
ただ上の画面からも分かるように、生成の指示に使う項目は、言葉以外にもけっこうありますよね。
なので、これら基本の項目をいったんバラして、いちばんシンプルなところから始めてみます。
- ※
- 生成画像:DreamShaper 8
概要:テキストからイメージ
- ◯
- 個別:特殊な画像〜一般の画像
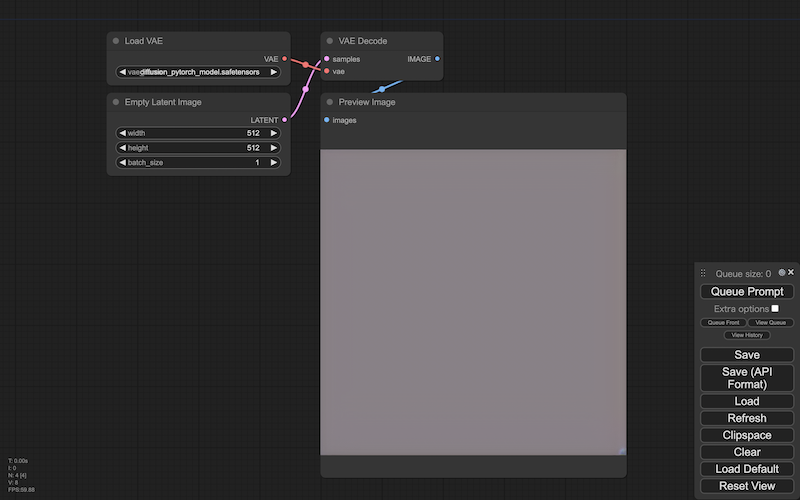
これは画像生成の、いちばんシンプルな構成です。
画像を生成するときは、このように特殊な画像から、一般の画像を生成します(empty latent image > preview image)。[※1][※2]
この段階では、ただの平板なイメージしか生成されません。ただすくなくとも、次の2つの指示が使えます:
- ・
- 画像の大きさ:縦(height)・横(width)
- ・
- 画像の枚数/バッチサイズ(batch size)
特殊な画像の大きさを変えると、生成される一般の画像の大きさも変わります(画像の縦/横の大きさは、特殊な画像も一般の画像も変わりません)。
特殊な画像の枚数を変えると、生成される一般の画像の枚数も変わります。
- ※1
- この特殊な画像は、一般の画像が持ついろいろな特徴を抽出したものです。ヒトが見てもなにを表しているのかよく分からない画像ですが(なので生成アプリもあえて表示しません)、機械はこの画像をあつかうことができますーー一般の画像にくらべて属性(=次元)の数がとても小さいので、生成するときのパソコンやサーバの負荷を小さくできる、という利点があります。
- ※2
- 特殊な画像は、潜在空間(latent space)と呼ばれる、より次元の数が小さいところにある、ともいえます。潜在空間にある画像を、一般の画像に戻すには、変分オートエンコーダ(VAE)と呼ばれる、変換のパーツを使います。とはいえここで使うのは、デコーダの方ですが(vae decode)ーーまた、この変換のパーツを使うには、そのふるまいを決めるパーツもいっしょに指定する必要があります(load vae)。
- ◯
- 個別:特殊な画像〜一般の画像+チェックポイント+サンプラ
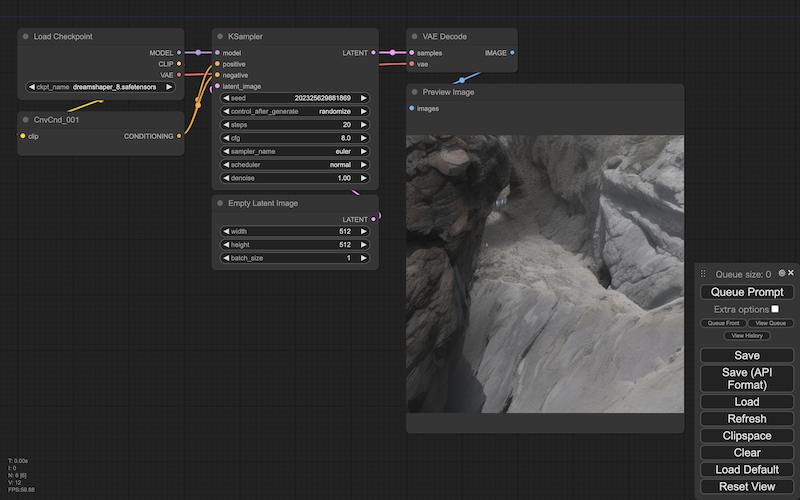
いろいろな画像を生成するとしても、まず生成の方向を決める必要があります。
その方向を決めるのが、画像生成のチェックポイントと呼ばれるパーツですーーチェックポイントは、ある枠組(=モデル)の、それぞれのバリエーションです(load checkpoint)。[※3][※4]
このチェックポイントに、サンプラと呼ばれる、生成の側面を決めるパーツを組み合わせますーーこうすることで、いろいろな画像を生成できるようになります(k sampler)。
この段階では、まだ言葉で指示することはできません。ただすくなくとも、次の3つの指示が使えます:
- ・
- サンプラの種類(sampler name)
- ・
- ステップ数(steps)
- ・
- シード(seed)
サンプラの種類は、画像を生成するときの、手法を指示しますーーこの手法もいろいろなやり方が提案されてきて、手法が違えば、生成されるイメージもそれなりに違ってきます。
ステップ数は、画像を生成するときの回数を指定しますーーサンプラが画像を生成するときは、曖昧なイメージを明瞭なイメージに変えていくのに、段階を踏みます。端的には、回数が小さければ、よりぼんやりとしたイメージになりがちです。回数が大きければ、よりはっきりしたイメージになりがちです。
シードは、画像を生成するときの基準になる数値ですーーこの数値を変えることで、生成の基準が変わり、生成されるイメージも変わります(逆にいえば、シードが同じなら、生成されるイメージはつねに同じになりますーーもちろん、ほかのすべての条件が同じであるかぎり、ですが)。[※5]
- ※3
- 画像生成のチェックポイントにはいろいろな種類がありますーー人物描写が得意なもの、背景描写が得意なもの、リアル調に特化したもの、アニメ調に特化したものーーどのようなイメージを生成したいかで、チェックポイントを選ぶことになります。
- ※4
- 画像生成のチェックポイントは、じっさいには3つのチェックポイントからできていますーーそれぞれ、u-net 、clip 、vae と呼ばれるものですーーu-net のチェックポイントは、U-Net と呼ばれる(潜在空間でイメージを生成する)構造のふるまいを決めます。clip のチェックポイントは、CLIP テキストエンコーダのふるまいを決めます[後述]。vae のチェックポイントは、変分オートエンコーダ(VAE)のふるまいを決めます(vae のチェックポイントは、単独でも提供されています)。
- ※5
- シードの数値を指示する項目もあります(control after generate)ーーこの項目で、シードの数値を固定にするか変動にするか、決めることができます。なお変動(インクリメントやランダム)にした場合、画像を生成したあとに、次の生成のための数値がセットされますーーなので生成後に再現したければ、履歴をさかのぼる必要があります。
- ◯
- 個別:特殊な画像〜一般の画像+チェックポイント+サンプラ+言葉の条件づけ
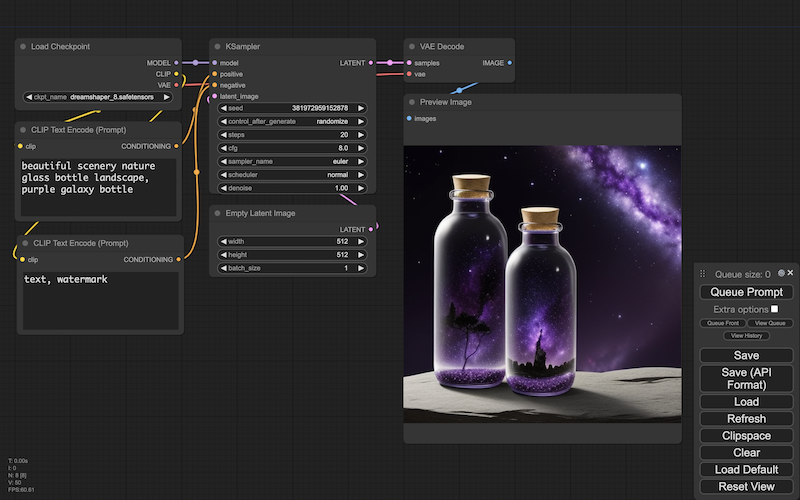
サンプラに、言葉で条件づけるパーツ(=CLIP テキストエンコーダ)を組み合わせることで、言葉で画像を生成できるようになります(clip text encoder)。[※6]
生成の言葉には、肯定的なものと否定的なものがありますーー画像のイメージは、肯定的な言葉には近づくように、否定的な言葉からは遠ざかるように、生成されます:
- ・
- プロンプト:ポジティブ(prompt: positive)
- ・
- プロンプト:ネガティブ(prompt: negative)
- ・
- CFG スケール(cfg)
生成に使う言葉を、プロンプトといいますーー肯定的な言葉は、ボジティブプロンプト、否定的な言葉は、ネガティブプロンプトといいます。
CFG スケールは、ボジティブプロンプト(肯定的な言葉)に、どれだけ近づけるかの度合を指示します。より大きな値になるほど、より近づきます。いっぽうネガティブプロンプト(否定的な言葉)は、その度合の出発点になります。[※7]
- ※6
- CLIP テキストエンコーダは、言葉と画像を比較できるモデルのひとつですーーここで言葉は、ベクトルと呼ばれる数値の並びに変換されます(埋め込み、ともいいます)。いっぽう生成途中の特殊な画像(潜在空間の画像)も、テンソルと呼ばれる数値の並びですーーこれらをさらに CLIP 向けのベクトルに変換することで、たがいにどれだけ似ているかを比較できるようになります。
- ※7
- ネガティブだからマイナスの方向に行く、というわけではありませんーーネガティブプロンプトで生成されるはずの画像を基準に、そこからどれだけ離れるかの度合が、CFG スケールですーー逆にいえば、ネガティブプロンプトで指定したような画像には到達しない、ということがこれで保証されます。
- ◯
- 全体:特殊な画像〜一般の画像+チェックポイント+サンプラ+言葉の条件づけ
これまでのパーツ群をまとめると、上の画面になります。
テキストからイメージを生成するので、t2i ともいいます。
概要:イメージからイメージ
- ◯
- 個別:一般の画像〜一般の画像
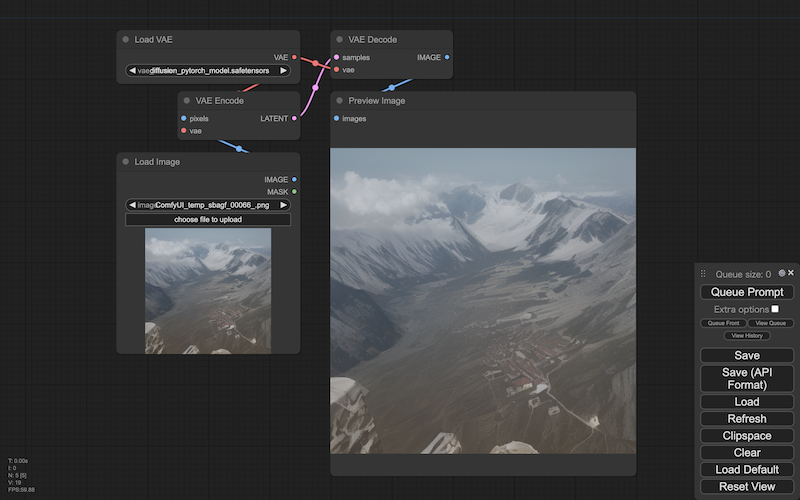
画像生成のいちばんシンプルな構成では、特殊な画像から生成されるのは、平板なイメージでした。
このときの特殊な画像は、じつはただの砂嵐(=ノイズ)だけが乗った状態です。
このノイズを取り除いていく過程が、じっさいの画像生成になります。
なので、特殊な画像に(ただのノイズではなく)なんらかのイメージを指定すれば、そのイメージを元にしたイメージを生成できるようになります(load image)。[※1]
- ※1
- イメージの元になる画像は、一般の画像が使えます。ただし一般の画像は、いったん特殊な画像(潜在空間の画像)に変える必要があります(画像生成は、特殊な画像を一般の画像に変える過程です)ーーこの変換にも、変分オートエンコーダ(VAE)を使いますーーただしこのとき使うのは、エンコーダと呼ばれる方になります(vae encode)。
- ◯
- 個別:一般の画像〜一般の画像+チェックポイント+サンプラ+言葉の条件づけ
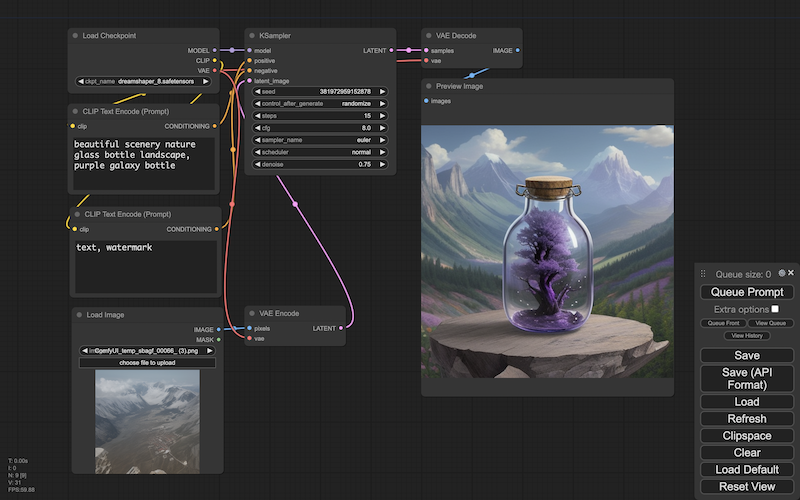
特殊な画像にイメージを使うなら、ノイズの取り除き方も指定できる必要があります:
- ・
- ノイズスケジューラの種類(scheduler)
- ・
- ノイズを除去する大きさ(denose)
ノイズをどのように除去していくかを決めるのが、ノイズスケジューラですーーこれも、いくつかの手法が提案されてきています。
また、スケジューラがノイズをどれだけ除去するかも、指定できます。
- ◯
- 全体:一般の画像〜一般の画像+チェックポイント+サンプラ+言葉の条件づけ
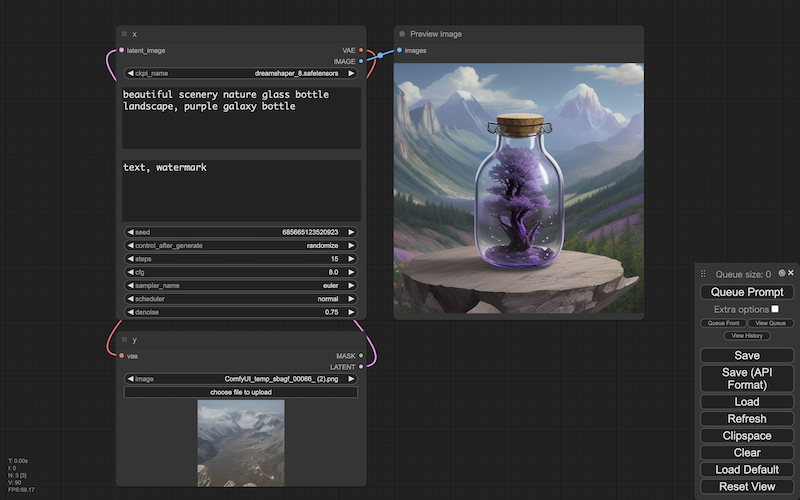
これまでのパーツ群をまとめると、上の画面になります。
イメージからイメージを生成するので、i2i ともいいます。
制約
以上、画像生成の概要を、生成アプリの基本の使い方からみてきました。
ただし、画像生成のモデルにはさまざまなものがありますーーいまは、Stability AI 社が提供する Stable Diffusion (SD) と呼ばれるモデルがよく使われていますが、これは、潜在拡散(LD)と呼ばれるモデルの、さらに商用版のひとつでしかありません。
ここでみてきた過程は、潜在拡散モデルにかぎったものです。