

ComfyUI からマルチモーダルの言語モデルを使い、生成した画像の解釈を、日本語で出力してみます。[※1]
- ※1
- 生成画像は、次のモデルを使用しています:
- ・
- https://civitai.com/models/4468/counterfeit-v30
関連
- ◯
- ComfyUI で画像生成 〜 なぜそこにつなぐのか:ComfyUI, Stable Diffusion
- ◯
- ComfyUI を、クラウドのコンテナに設置する:ComfyUI, Docker, GCP
検証
- ◯
- サーバ
- ・
- クラウド:GCP
- ・
- コンテナ:Docker
- ・
- ホスト:Ubuntu 22.04
- ・
- ゲスト:Ubuntu 22.04
- ◯
- クライアント
- ・
- パソコン:macOS
概要
ComfyUI は、ノードの内容を Python で書くことができますーーなので、さまざまな機械学習の成果を、かんたんに取り込むことができます。
ここでは、ComryUI からマルチモーダルの言語モデルを使い、生成した画像の解釈を、言語モデルから出力してみます(せっかくなので、日本語で出力できるモデルを使います)。
次のリポジトリに、オープンソースのマルチモーダル言語モデル(LLaVA)を使えるノードがあります:
- ・
- https://github.com/ceruleandeep/ComfyUI-LLaVA-Captioner
設置
次の手順で設置します:
ComfyUI のカスタムノードのフォルダに直接、リポジトリの内容を設置します:[※1]
$ cd ${directory_project}/ComfyUI/custom_nodes
$ git clone --depth=1 https://github.com/ceruleandeep/ComfyUI-LLaVA-Captioner.git
ホスト側で、CUDA ツールキットを設置しますーーその実行ファイル群とライブラリ群をふくむフォルダをマウントし、コンテナを起動します:[※2]
$ apt install cuda=12.1.1-1
$ docker run -it --rm --gpus all -v ${directory_project}:${directory_project} -v ${directory_models}:${directory_models} -v /usr/local/cuda-12.1:/usr/local/cuda -p <port_target>:8188 --name ${container} ${image}
コンテナで、ライブラリ群を設置します:
$ apt update
$ apt install git
$ export PATH=${PATH}:/usr/local/cuda/bin
$ export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda/lib64
$ cd ${directory_project}/ComfyUI/custom_nodes/ComfyUI-LLaVA-Captioner
$ python install.py
マルチモーダルの言語モデルを取得しますーー軽量なモデルとして LLaVA-v1.5-7B を、日本語も使えるモデルとして ShareGPT4V を、ともに量子化された版を使います:
# マルチモーダル言語モデルの取得(llava-v1.5-7b-Q4_K.gguf):
$ cd /exp001/llm
$ wget https://huggingface.co/jartine/llava-v1.5-7B-GGUF/resolve/main/llava-v1.5-7b-Q4_K.gguf
$ wget https://huggingface.co/jartine/llava-v1.5-7B-GGUF/resolve/main/llava-v1.5-7b-mmproj-Q4_0.gguf
$ cd ${HOME}/system/vol101/prj/ComfyUI/custom_nodes/ComfyUI-LLaVA-Captioner/models
$ ln -s /exp001/llm/llava-v1.5-7b-Q4_K.gguf llava-v1.5-7b-Q4_K.gguf
$ ln -s /exp001/llm/llava-v1.5-7b-mmproj-Q4_0.gguf llava-v1.5-7b-mmproj-Q4_0.gguf
# マルチモーダル言語モデルの取得(ShareGPT4V-f16.gguf):
$ cd /exp001/llm
$ wget https://huggingface.co/Galunid/ShareGPT4V-gguf/resolve/main/ShareGPT4V-f16.gguf
$ wget https://huggingface.co/Galunid/ShareGPT4V-gguf/resolve/main/mmproj-model-f16.gguf
$ cd ${HOME}/system/vol101/prj/ComfyUI/custom_nodes/ComfyUI-LLaVA-Captioner/models
$ ln -s /exp001/llm/ShareGPT4V-f16.gguf ShareGPT4V-f16.gguf
$ ln -s /exp001/llm/mmproj-model-f16.gguf mmproj-model-f16.gguf
ComfyUI には、テキストを動的に表示するノードがないので、次のリポジトリから取得します:
- ・
- https://github.com/pythongosssss/ComfyUI-Custom-Scripts
たくさんのノード群がパッケージとして提供されていますが、とりあえず必要なのは、テキストの動的表示だけですーーなのでここでは、そのノードだけを取得して使えるようにします。次のフォルダ群に、次のリソース群を転記し:
$ mkdir ${directory_project}/comfyui-trials_ver_${yyyy_mm_dd_nnn}
$ cd ${directory_project}/comfyui-trials_ver_${yyyy_mm_dd_nnn}
< https://github.com/pythongosssss/ComfyUI-Custom-Scripts/blob/main/py/show_text.py
$ mkdir -p web/js
$ cd ${directory_project}/comfyui-trials_ver_${yyyy_mm_dd_nnn}/web/js
< https://github.com/pythongosssss/ComfyUI-Custom-Scripts/blob/main/web/js/showText.js
$ cd ${directory_project}/ComfyUI/custom_nodes
$ ln -s ${directory_project}/comfyui-trials_ver_${yyyy_mm_dd_nnn} comfyui-trials
このノード単体のための、設定ファイルを記述します:
- ・
- ${directory_project}/comfyui-trials_ver_${yyyy_mm_dd_nnn}/__init__.py
from .show_text import ShowText
NODE_CLASS_MAPPINGS = {
"ShowText|pysssss": ShowText,
}
NODE_DISPLAY_NAME_MAPPINGS = {
"ShowText|pysssss": "Show Text 🐍",
}
WEB_DIRECTORY = "./web"
- ※1
- インストーラがシンボリックリンクを認識しないので、直接設置する必要があります(ほんらいカスタムノードは、シンボリックリンクにしたいんですけどねーーインストーラを書き換えるのも、バージョンアップのとき面倒なりますし)。
- ※2
- これは、インストーラが CUDA ツールキットのライブラリ群を参照するためですーーなお CUDA のバージョンは、いちおう、コンテナ側の Pytorch に同梱された CUDA ランタイムと同じにしています(バージョンを合わせるのは必須ではありません):
$ python > import torch > torch.version.cuda '12.1'
利用
コンテナは、通常どおり起動します(通常の利用では、CUDA ツールキットのマウントは必要ありません):
$ docker run -it --rm --gpus all -v ${directory_project}:${directory_project} -v ${directory_models}:${directory_models} -p <port_target>:8188 --name ${container} ${image}
コンテナでは、(プレビューは不要なので)シンプルにアプリを起動します:
$ cd /system/vol101/prj/ComfyUI; python main.py --listen
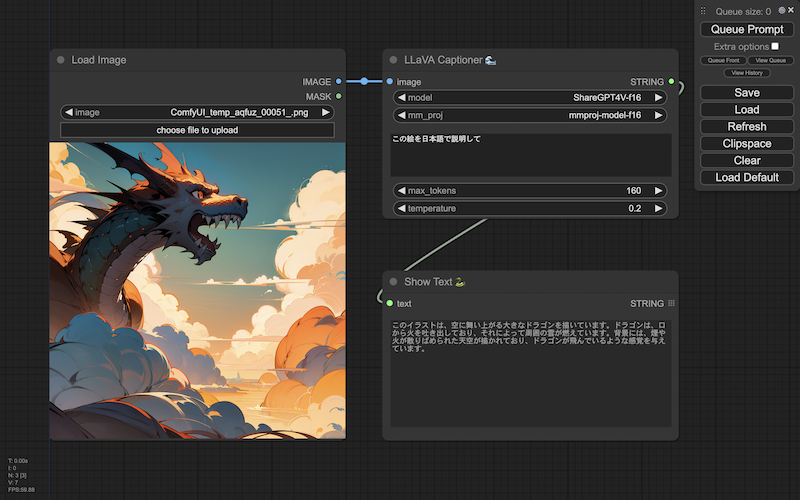
次のように、画像認識のノード(LLaVA Captioner)に日本語で質問することで:
この絵を日本語で説明して
解釈した画像の内容を、日本語で答えてくれます:
このイラストは、空に舞い上がる大きなドラゴンを描いています。ドラゴンは、口から火を吐き出しており、それによって周囲の雲が燃えています。背景には、煙や火が散りばめられた天空が描かれており、ドラゴンが飛んでいるような感覚を与えています。