

ComfyUI の OpenPose Editor を使って、リアルタイムなポーズの変更を、ウェブブラウザで実行します。[※1][※2]
- ※1
- 生成画像は、次のモデルを使用しています:
- ・
- https://civitai.com/models/4468/counterfeit-v30
- ※2
- この動画は、4倍速です。
関連
- ◯
- ComfyUI で画像生成 〜 なぜそこにつなぐのか:ComfyUI, Stable Diffusion
- ◯
- ComfyUI を、クラウドのコンテナに設置する:ComfyUI, Docker, GCP
検証
- ◯
- サーバ
- ・
- クラウド:GCP
- ・
- コンテナ:Docker
- ・
- ホスト:Ubuntu 22.04
- ・
- ゲスト:Ubuntu 22.04
- ◯
- クライアント
- ・
- コンテナ:Docker Desktop
- ・
- ホスト:macOS
- ・
- ゲスト:Ubuntu 22.04
概要
高速生成の LCM LoRA モデルが提供され、画像生成でも、ほぼリアルタイムな描写ができるようになりました。
これを ComfyUI で実行する場合、Krita と連携させることが多いかもしれませんがーーそれだと、Krita の利用が前提になります。
ここでは、ComfyUI の通常の編集画面で使える OpenPose Editor から、リアルタイムなポーズ変更を、ウェブブラウザ上でやってみます。
利用
とはいえ OpenPose Editor には、(ControlNet などが認識した)ポーズ情報を取り込むポートがありませんーーなので、最初に生成画像のポーズ情報を OpenPose Editor に反映させるところは、手動で行います。
まず、次のリポジトリから、ControlNet 向けの画像認識ライブラリ群を取得します:
- ・
- https://github.com/Fannovel16/comfyui_controlnet_aux
$ cd ${directory_project}
$ git clone --depth=1 https://github.com/Fannovel16/comfyui_controlnet_aux
$ mv comfyui_controlnet_aux comfyui_controlnet_aux_ver_${yyyy_mm_dd_nnn}
$ cd ${directory_project}/ComfyUI/custom_nodes
$ ln -s ${directory_project}/comfyui_controlnet_aux_ver_${yyyy_mm_dd_nnn} comfyui_controlnet_aux
生成画像からポーズ情報を得る、ワークフローを作りますーーここで使うポーズ認識のノード(DWPose Estimation)は、認識した情報をワークフロー上に出力します(ブラウザの画面には表示されません):
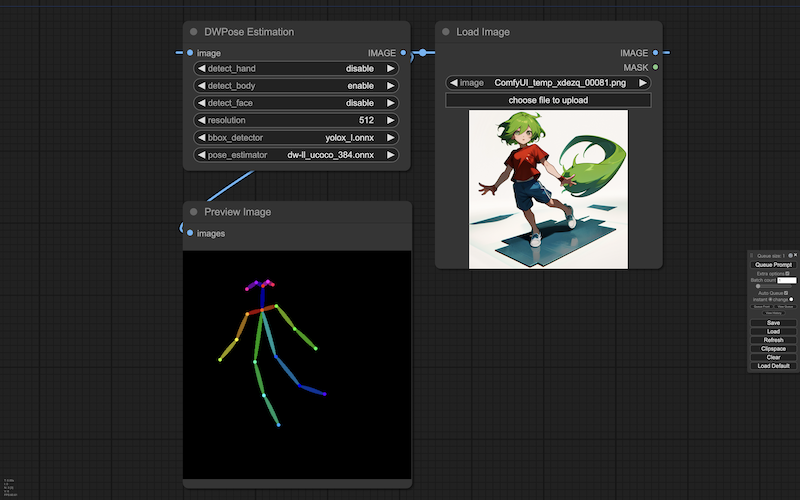
ポーズ情報の出力を得るため、ComfyUI のヒストリ機能を使いますーーヒストリにアクセスし:
http://<address_server>:<port_target>/history
目的のワークフローのハッシュ化された ID を確かめます(すぐに見つけられるようにするには、画像認識の実行前に、ヒストリをクリアしておきます):
...
{"<hash_workflow>": ...
...
じっさいにアクセスできるかどうか、そのワークフローの ID をヒストリの引数にし、出力してみます:
http://<address_server>:<port_target>/history/<hash_workflow>
このワークフローから、 ポーズ情報(OpenPose の標準形式/JSON形式)を得るためのスクリプトは、次になります(これは、上記のリポジトリのコードを参考にしていますが、すこし修正しています):
- ・
- ${directory_application}/getopp.py
import sys
import json, urllib.request
server_address = sys.argv[1]
prompt_id = sys.argv[2]
def get_history(prompt_id):
with urllib.request.urlopen("http://{}/history/{}".format(server_address, prompt_id)) as response:
return json.loads(response.read())
history = get_history(prompt_id)[prompt_id]
for node_id in history['outputs']:
node_output = history['outputs'][node_id]
if 'openpose_json' in node_output:
sys.stdout.write(node_output['openpose_json'][0])
また OpenPose Editor は独自の形式でポーズ情報を保持するので、OpenPose の標準形式のままでは適用できませんーーなので、標準形式から独自形式に変換します:
- ・
- ${directory_application}/cnvopp.py
import sys
import json
stropp = sys.stdin.read()
dctopp = json.loads(stropp)
wdhcvs = dctopp['canvas_width']
hghcvs = dctopp['canvas_height']
lstopp = dctopp['people'][0]['pose_keypoints_2d']
lstope = []
while lstopp != []:
x = lstopp.pop(0)
y = lstopp.pop(0)
c = lstopp.pop(0)
lstope.append([x,y])
dctope = {'width': wdhcvs, 'height': hghcvs, 'keypoints': [lstope]}
jsnope = json.dumps(dctope)
sys.stdout.write(jsnope)
これらのスクリプトを使い、画像認識のワークフローから、OpenPose Editor のためのポーズ情報を取得します:
$ python ${directory_application}/getopp.py ${address_server}:<port_target> <hash_workflow> | python ${directory_application}/cnvopp.py > /tmp/a.json
取得したポーズ情報を OpenPose Editor に適用することで(出力された JSON ファイルの読み込み)、エディタの OpenPose のボーンが、生成画像のポーズと同じになります:
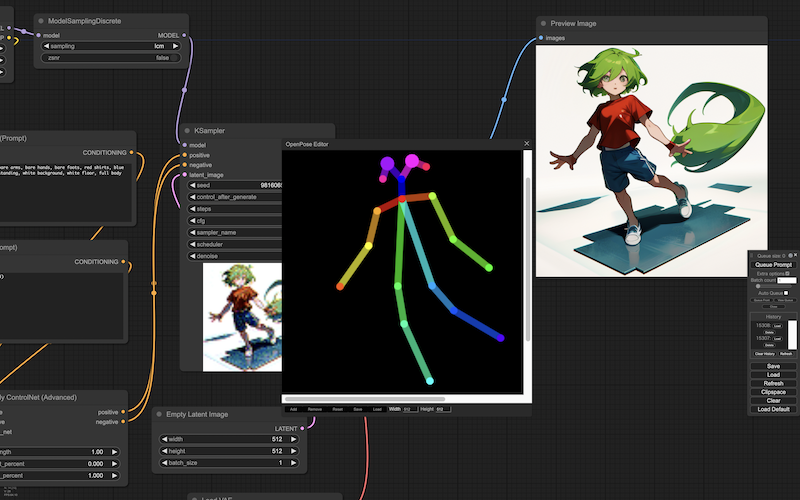
ここから、リアルタイムに画像を生成します。
オートキューをオンにし、生成を始めますーーOpenPose Editor でポーズを変えていくと、画像の人物のポーズも、連動して変わっていきます:
> extra options: <yes> > batch count: 1 > auto queue: <yes> # 連続生成を開始: > [queue prompt] # 連続生成を停止: > auto queue: <nil>