

画像生成モデルで動画化したキャラを、ステレオグラムで立体化し、VR/MR で対面してみました:
- ※1
- 生成画像は、次のモデルを使用しています:
- ・
- https://huggingface.co/WarriorMama777/OrangeMixs
関連
- ◯
- ComfyUI で画像生成 〜 なぜそこにつなぐのか:ComfyUI, Stable Diffusion
- ◯
- ComfyUI を、クラウドのコンテナに設置する:ComfyUI, Docker, GCP
- ◯
- ComfyUI の API を使う:ComfyUI, API, JSON, Python, Docker, GCP
検証:修正版
- ◯
- アプリ
- ・
- 画像生成:ComfyUI
- ◯
- VR/MR
- ・
- PC〜HMD間ストリミーング:Virtual Desktop
- ・
- HMD:Quest 2
- ◯
- サーバ
- ・
- クラウド:GCP
- ・
- コンテナ:Docker
- ・
- ホスト:Ubuntu 22.04
- ・
- ゲスト:Ubuntu 22.04
検証:通常版
- ◯
- アプリ
- ・
- 画像生成:ComfyUI
- ・
- 画像編集:GIMP
- ◯
- VR/MR
- ・
- PC〜HMD間ストリミーング:Virtual Desktop
- ・
- HMD:Quest 2
- ◯
- クライアント
- ・
- コンテナ:Docker Desktop
- ・
- ホスト:macOS
- ・
- ゲスト:Ubuntu 22.04
- ◯
- サーバ
- ・
- クラウド:GCP
- ・
- コンテナ:Docker
- ・
- ホスト:Ubuntu 22.04
- ・
- ゲスト:Ubuntu 22.04
概要
いまは、一枚の画像から深度を推定する技術が進歩し、立体視化もそれほど違和感のないレベルに達しています。また画像生成モデルだけでも、あるていどの動画生成は可能になっています。
ここでは、キャラの動画を立体視できるようにして、VR/MR(パススルー)で対面してみます。
前提
ComfyUI では、次のカスタムノード群を使います:
- ◯
- 動画生成(AnimateDiff)
- ・
- https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved
文章(プロンプト)から生成される画像を、さらに動画化します。
- ◯
- 物体検出(Rembg/U2-Net)[※1]
- ・
- https://github.com/cubiq/ComfyUI_essentials[※2]
- ・
- https://github.com/Jcd1230/rembg-comfyui-node[※3]
動画のフレーム(画像)群から物体(キャラ)を検出し、背景と切り離しますーーこれで、目的の対象だけを表示できるようになります。
- ◯
- 深度推定(ControlNet Auxiliary Preprocessors/MiDaS)[※4]
- ・
- https://github.com/Fannovel16/comfyui_controlnet_aux
動画のフレーム(画像)群から奥行きを推定し、深度マップ群を作ります。
- ◯
- 立体視化(NegiTools/Stereo Image Generator)
- ・
- https://github.com/natto-maki/ComfyUI-NegiTools[※5]
動画のフレーム(画像)群とその深度マップ群から、ステレオグラムのフレーム群を作成しますーーこれで、VR/MR で、対象を立体視できるようになります。
- ※1
- Rembg は、汎用の物体検出モデル U2-Net を使うコードの総称です。
- ※2
- このカスタムノードは、バッチ処理に対応し、アニメ調を検出できるモデルも使うことができます。ただしパッケージの構成は、物体検出のノード以外にもさまざまなノードがふくまれたものです(アプリ本体の構成によっては、依存関係に問題が出るかもしれません)。
- ※3
- このカスタムノードは、バッチ処理に対応しておらず、アニメ調を検出できるモデルも使えません。ただしパッケージの構成は、物体検出のノードのみですーーこのノードでアニメ調のキャラを使うなら、フラットな塗りだと誤検出も多いので、厚塗り系と呼ばれる生成モデルを使う方がいいかもしれません(それでもフラットな塗りのキャラを使いたいならーーたとえば、ここでの処理は深度マップを生成するので、GIMP などを使い、一定の深さの箇所(背景)を黒の画像と合成する、といったやり方があるかも)。
- ※4
- ここでは深度マップの生成に、MiDaS / control_v11f1p_sd15_depth を使っていますーー生成は軽く速いものの、推定の精度はそれなりですーーキャラがリアル調なら Marigold、アニメ調ならLine2Depth (Line2Normalmap) などを使うと、より精度の高い深度マップが生成されるはずです:
- ・
- https://github.com/kijai/ComfyUI-Marigold
- ・
- https://huggingface.co/toyxyz/Line2Depth_sd1.5
- ※5
- このカスタムノードは、バッチ処理に対応していません。また(おそらく入力される深度マップの想定が違うため、ここでの使用のしかただと)平行法(left-right)のステレオグラムを作成するのに、交差法(R-L)を選択する必要がありますーーコード自体は、次の A1111 / Stable Diffusion web UI 向けプラグインのラッパです:
- ・
- https://github.com/thygate/stable-diffusion-webui-depthmap-script
設置〜作成
カスタムノード群の設置とステレオグラムの作成は、次の2とおりの手順を示しています:
- ・
- 修正版……設置がノーマルでない代わりに、作成はノンストップになります[※1]
- ・
- 通常版……作成がノンストップでない代わりに、設置はノーマルになります
- ※1
- ステレオグラムのカスタムノードがバッチ処理に対応していないので、これを修正したものを使いますーーこれですべての処理を、ワークフロー上で完結させることができます。
設置:修正版
- ※
- この手順は、設置がノーマルでない代わりに、作成はノンストップになります。
次の手順で、物体検出/立体視化のカスタムノード群を設置します:
- ◯
- 物体検出(Rembg/U2-Net)
カスタムノードのフォルダを作成します:
$ cd ${directory_project}
$ mkdir ComfyUI_essentials_002
$ cd ${directory_project}/ComfyUI/custom_nodes
$ ln -s ${directory_project}/ComfyUI_essentials_002 ComfyUI_essentials_002
カスタムノードのファイルを作成します:
- ・
- ComfyUI_essentials_002/__init__.py
import torch
import torchvision.transforms.v2 as T
def p(image):
return image.permute([0,3,1,2])
def pb(image):
return image.permute([0,2,3,1])
class RemBGSession:
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"model": (["u2net: general purpose", "u2netp: lightweight general purpose", "u2net_human_seg: human segmentation", "u2net_cloth_seg: cloths Parsing", "silueta: very small u2net", "isnet-general-use: general purpose", "isnet-anime: anime illustrations", "sam: general purpose"],),
"providers": (['CPU', 'CUDA', 'ROCM', 'DirectML', 'OpenVINO', 'CoreML', 'Tensorrt', 'Azure'],),
},
}
RETURN_TYPES = ("REMBG_SESSION",)
FUNCTION = "execute"
CATEGORY = "essentials"
def execute(self, model, providers):
from rembg import new_session as rembg_new_session
model = model.split(":")[0]
return (rembg_new_session(model, providers=[providers+"ExecutionProvider"]),)
class ImageRemoveBackground:
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"rembg_session": ("REMBG_SESSION",),
"image": ("IMAGE",),
},
}
RETURN_TYPES = ("IMAGE", "MASK",)
FUNCTION = "execute"
CATEGORY = "essentials"
def execute(self, rembg_session, image):
from rembg import remove as rembg
image = p(image)
output = []
for img in image:
img = T.ToPILImage()(img)
img = rembg(img, session=rembg_session)
output.append(T.ToTensor()(img))
output = torch.stack(output, dim=0)
output = pb(output)
mask = output[:, :, :, 3] if output.shape[3] == 4 else torch.ones_like(output[:, :, :, 0])
return(output[:, :, :, :3], mask,)
NODE_CLASS_MAPPINGS = {
"RemBGSession+": RemBGSession,
"ImageRemoveBackground+": ImageRemoveBackground
}
NODE_DISPLAY_NAME_MAPPINGS = {
"RemBGSession+": "🔧 RemBG Session",
"ImageRemoveBackground+": "🔧 Image Remove Background"
}
ライブラリ群を設置します(ComfyUI が動く環境で):[※1]
$ pip install rembg[gpu] $ pip install kornia
- ◯
- 立体視化(Stereo Image Generator)
カスタムノードのフォルダを作成します:
$ cd ${directory_project}
$ mkdir ComfyUI-NegiTools_002
$ cd ${directory_project}/ComfyUI/custom_nodes
$ ln -s ${directory_project}/ComfyUI-NegiTools_002 ComfyUI-NegiTools_002
ラッパ元のソースコードを取得しますーーステレオグラムの生成に必要なのは、次のファイルのみです:
- ・
- https://github.com/thygate/stable-diffusion-webui-depthmap-script/blob/main/src/stereoimage_generation.py
$ cd ${directory_project}/ComfyUI-NegiTools_002
$ mkdir -p negi dependencies/stable-diffusion-webui-depthmap-script/src
$ cd ${directory_project}/ComfyUI-NegiTools_002/dependencies/stable-diffusion-webui-depthmap-script/src
$ wget https://raw.githubusercontent.com/thygate/stable-diffusion-webui-depthmap-script/main/src/stereoimage_generation.py
初期化ファイルを作成します:
- ・
- ComfyUI-NegiTools_002/__init__.py
from .negi.stereo_image_generator_002 import StereoImageGenerator_002
NODE_CLASS_MAPPINGS = {
"NegiTools_StereoImageGenerator_002": StereoImageGenerator_002
}
NODE_DISPLAY_NAME_MAPPINGS = {
"NegiTools_StereoImageGenerator_002": "StereoImageGenerator_002 🧅"
}
カスタムノードを修正します:
- ・
- https://github.com/natto-maki/ComfyUI-NegiTools/blob/master/negi/stereo_image_generator.py
これは、[1]バッチ処理ができるようコードを追加し、[2]深度マップを補正するコードを削除したものですーーこの修正により、(API などを介することなく)ノンストップで動画生成から立体視化まで行え、ステレオグラムも平行法(L-R)が使えるようになります(なお(VR/MR には不要ということもあり)、平行法以外のステレオグラム生成のコードも削除しています):
- ・
- ComfyUI-NegiTools_002/negi/stereo_image_generator_002.py
import importlib
import numpy as np
import torch
import torchvision
_dependency_dir = "dependencies"
_repository_name = "stable-diffusion-webui-depthmap-script"
class StereoImageGenerator_002:
@classmethod
def INPUT_TYPES(cls):
return {
"required": {
"l_image": ("IMAGE",),
"l_depth_image": ("IMAGE",),
"divergence": ("FLOAT", {
"default": 5.0, "min": 0.05, "max": 10.0, "step": 0.01, "round": 0.001, "display": "slider"
}),
"stereo_offset_exponent": ("FLOAT", {
"default": 1.0, "min": 0.1, "max": 3.0, "step": 0.1, "round": 0.01, "display": "slider"
}),
"fill_technique": ([
"polylines_sharp", "polylines_soft", "naive", "naive_interpolating", "none"
],),
}
}
RETURN_TYPES = ("IMAGE",)
RETURN_NAMES = ("STEREO_IMAGE",)
FUNCTION = "doit"
OUTPUT_NODE = False
CATEGORY = "Generator"
def doit(self, l_image, l_depth_image, divergence, stereo_offset_exponent, fill_technique):
m = importlib.import_module(
"." + ".".join([_dependency_dir, _repository_name, "src", "stereoimage_generation"]),
".".join(__name__.split(".")[:-2]))
modes = ["left-right"]
l = []
for (i, _) in enumerate(l_image):
image = torchvision.transforms.functional.to_pil_image(torch.permute(l_image[i], (2, 0, 1)))
depth_map = l_depth_image[i].to('cpu').detach().numpy()[:, :, 0]
images = m.create_stereoimages(
image, depth_map, divergence, modes=modes,
stereo_offset_exponent=stereo_offset_exponent, fill_technique=fill_technique)
l.append(torchvision.transforms.functional.to_tensor(images[0]).permute(1, 2, 0).unsqueeze(0))
return (torch.cat(l),)
- ※1
- 物体検知のモデル U2-Net は、ホームディレクトリに配置されます:
- ・
- ${HOME}/.u2net/u2net.onnx
作成:修正版
- ※
- この手順は、設置がノーマルでない代わりに、作成はノンストップになります。
次の手順で、動画のステレオグラム群を作成します:
次のフローを実行すれば、動画のステレオグラム(GIF 形式)がノード上に生成されますーーこのノードから、ファイルをローカルに保存します。:
- ・
- ${directory_development}/cnf/try004_workflow_stereogram.json
設置:通常版
- ※
- この手順は、作成がノンストップでない代わりに、設置はノーマルになります。
次の手順で、物体検出/立体視化のカスタムノード群を設置します:
- ◯
- 物体検出(Rembg/U2-Net)
カスタムノードを取得します:
$ cd ${directory_project}
$ git clone --depth=1 https://github.com/Jcd1230/rembg-comfyui-node.git
$ cd ${directory_project}/ComfyUI/custom_nodes
$ ln -s ${directory_project}/rembg-comfyui-node rembg-comfyui-node
ライブラリ群を設置します(ComfyUI が動く環境で):[※1]
$ pip install rembg[gpu] $ pip install kornia
- ◯
- 立体視化(Stereo Image Generator)
カスタムノードのフォルダを作成します:[※2]
$ cd ${directory_project}
$ mkdir ComfyUI-NegiTools_002
$ cd ${directory_project}/ComfyUI/custom_nodes
$ ln -s ${directory_project}/ComfyUI-NegiTools_002 ComfyUI-NegiTools_002
カスタムノードのファイルを取得しますーーステレオグラムの生成に必要なのは、次のファイルのみです:
- ・
- https://github.com/natto-maki/ComfyUI-NegiTools/blob/master/negi/stereo_image_generator.py
- ・
- https://github.com/natto-maki/ComfyUI-NegiTools/blob/master/negi/noise_image_generator.py
$ cd ${directory_project}/ComfyUI-NegiTools_002
$ mkdir negi
$ cd ${directory_project}/ComfyUI-NegiTools_002/negi
$ wget https://raw.githubusercontent.com/natto-maki/ComfyUI-NegiTools/master/negi/stereo_image_generator.py
$ wget https://raw.githubusercontent.com/natto-maki/ComfyUI-NegiTools/master/negi/noise_image_generator.py
初期化ファイルを作成します:
- ・
- ComfyUI-NegiTools_002/__init__.py
from .negi.stereo_image_generator import StereoImageGenerator
NODE_CLASS_MAPPINGS = {
"NegiTools_StereoImageGenerator": StereoImageGenerator
}
NODE_DISPLAY_NAME_MAPPINGS = {
"NegiTools_StereoImageGenerator": "Stereo Image Generator 🧅"
}
- ※1
- 物体検知のモデル U2-Net は、ホームディレクトリに配置されます:
- ・
- ${HOME}/.u2net/u2net.onnx
- ※2
- ノードが最初に使われるときに、ラッパするライブラリを取得するため、次のリポジトリからフォルダ内に、コード群が配置されます:
- ・
- https://github.com/thygate/stable-diffusion-webui-depthmap-script
作成:通常版
- ※
- この手順は、作成がノンストップでない代わりに、設置はノーマルになります。
次の手順で、動画のステレオグラム群を作成します:
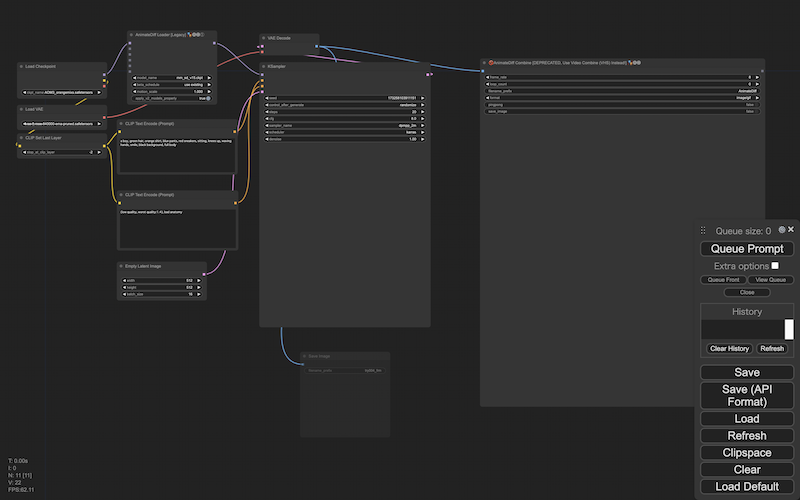
まず、動画のフレーム群を生成しますーー最初は、Save Image ノードは無効にしておいた方がいいかもしれません。
生成結果を動画(GIF )で確認しつつ、プロンプトやシードを決めていきます。決まったら、履歴からその状態に戻り、Save Image ノードを有効にします。ふたたび生成を実行すると、動画のフレームになる画像群が、output フォルダに保存されます:
- ・
- ${directory_development}/cnf/try004_workflow_animatediff.json
フォルダ output に生成されたフレーム群を、フォルダ input に移します:
$ cd ${directory_comfyui}/input
$ mv ${directory_comfyui}/output/??????_???_?????_.png .
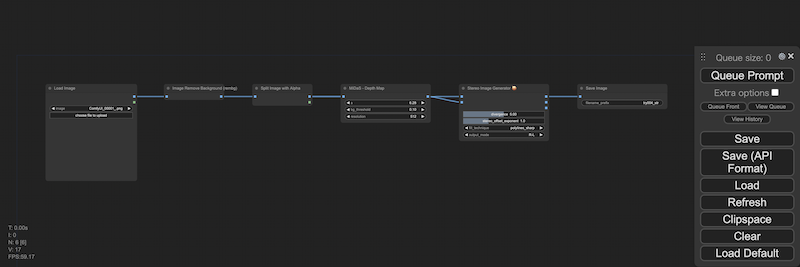
ComfyUI の API を使って、動画のフレーム群をステレオグラムのフレーム群に変換します。
元になるワークフローは、画像1枚ごとに、[1]背景を抜く〜[2]深度マップを作る〜[3]ステレオグラムのフレームを作る、ように構成します(なお、Rembg ノードが出力する背景は透過状態(アルファチャネルでの指定)になるので、Split Image with Alpha ノードを介して(Stable Diffusion があつかえる)通常の画像のマスクに変換します)。
このワークフローを、フレームの枚数分だけ繰り返すよう、スクリプトを作成します。このスクリプトを、Python を実行できる環境から、ComfyUI が動く環境に対し、実行します:[※1]
- ・
- ${directory_development}/cnf/try004_workflow_api_stereogram.json
- ・
- ${directory_development}/bin/try004.py
import sys
import time
import json
from urllib import request
def reqcmf(dctflw):
prompt = {'prompt': dctflw}
conweb = json.dumps(prompt).encode('utf-8')
reqweb = request.Request(f"{urltgt}prompt", data=conweb)
request.urlopen(reqweb)
urltgt = sys.argv[1]
strflw = sys.stdin.read()
dctflw = json.loads(strflw)
l = list(range(1,17))
for i in l:
dctflw['2']['inputs']['image'] = 'try004_frm_' + f'{i:05}' + '_.png'
reqcmf(dctflw)
time.sleep(1)
$ cat ${directory_development}/cnf/try004_workflow_api_stereogram.json | python ${directory_development}/bin/try004.py http://${server}:${port}/
作成されたステレオグラムのフレーム群を取得します:
$ cd ${directory_working}
$ scp ${user}@${server}:${directory_comfyui}/output/'??????_???_?????_.png' .
画像編集アプリの GIMP で、フレーム群から動画ファイル(GIF)を作ります:[※2]
> file open: <image_1>.png
> open as layers: <image_2>.png, ..., <image_N>.png # 一括での選択可
> filters > animation >
> optimize (for gif)
> playback # 再生を確認
> file > export as
> select file type (by extension)
> <image>.gif
> [export]
> as animation: <yes>

- ※1
- ここのカスタムノードの”Image batch To Image List”を使っても、たんにテンソルをリストに変換するだけでしょうし……:
- ・
- https://github.com/ltdrdata/ComfyUI-Impact-Pack
- ※2
- このステレオグラムは、平行法でみることができますーー連続した画像でも、統一した立体感が与えられていることを確認できると思います(統一感はあるものの、右足の遠近感が微妙ですね……ただこの生成画像だとこうするしかなさそうで、深度推定はがんばってると思います)。
利用
動画ファイル(GIF)を、Virtual Desktop Streamer が動く環境に移します。
HMDで Virtual Desktop を実行し、動画ファイル(GIF)を画像ビューアで開きますーーデスクトップ画面のモードを、SBS (Side-by-Side) + Transparency にすることで、生成した動くキャラと MR で対面できます:[※1][※2][※3]
> menu (bottom) > full sbs > menu (top) > transparency
- ※1
- 動画の上下がはみ出すときは、ディスプレの向きの設定を縦にするなどし、表示できる領域を確保します。
- ※2
- Windows 既定の画像ビューアや、その他のビューアも使えます(IrfanView, ...)。
- ※3
- ここでクロマキーが使えればいいんですけどねーーVirtual Desktop のデスクトップ画面は、黒色を透過させるだけですーーSteamVR のメディアプレイヤなら(Virtual Desktop のゲーム内になるので)SBS でもクロマキーが使えますが、画面の位置調整が煩雑など、使い勝手がよくありませんしーー一長一短です……
感想
目の前にいるキャラは、奥行きがあり動いてもいるので、じっさいにその場にいるように感じられますーーこれがたった数文字のプロンプトから生まれた存在だと考えると、感慨深いものがありますね。[※1][※2]
- ※1
- いまのところただの動画なので、触れてもスカスカな状態ですーーただ深度マップはもっているので、HMDの深度センサと組み合わせれば、<触れる>感触を得ることも可能ですーーこれがリアルタイムに生成できるようになれば、インタラクティブ性をもたせることもできるでしょうし、物理演算をふくめた多彩な反応が得られそうです。
- ※2
- もちろんその数文字のプロンプトの背後には、膨大な数の創作者(絵画〜写真)の熱意と努力の成果がありますーー生成モデルの普及で、それらの利用のしかたが、<個別の作品を鑑賞・体験する>というかたちから、<作品の集合を融合・体験する>というかたちに変わってきていますーー問題のひとつは、もともとあった<出典>(作家と作品など)という構造が、フラットになってしまっている、という点です。ここをどう解決していくかが、技術側の課題といえそうです。